- Published on
- •👁️
ClickHouse DB
- Authors

- Name
- River
상세 설명
ClickHouse는 원래 Linux 환경을 기준으로 개발되었다. Windows에서 직접 설치하려면 WSL2가 필요하므로, Docker Desktop을 이용하여 Docker로 구성한다.
Docker 환경 준비
Docker 설치 확인
docker --version docker-compose --versionClickHouse 작업 디렉토리 생성
mkdir clickhouse-dev cd clickhouse-dev
docker-compose.yml 구성
services:
clickhouse:
image: clickhouse/clickhouse-server:latest
container_name: clickhouse-server
ports:
- "8123:8123" # HTTP 포트
- "9000:9000" # Native 포트
- "9009:9009" # HTTP/S 포트
volumes:
- clickhouse-data:/var/lib/clickhouse
- ./config:/etc/clickhouse-server/config.d
- ./users:/etc/clickhouse-server/users.d
environment:
CLICKHOUSE_USER: admin
CLICKHOUSE_PASSWORD: 1234
CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT: 1
ulimits:
nofile:
soft: 262144
hard: 262144
volumes:
clickhouse-data:
볼륨 마운트
clickhouse-data- 이름 있는 볼륨
- ClickHouse 내부 데이터 저장 경로와 연결
./config- 바인드 마운트
- 직접 만든 커스텀 설정 파일(
custom.xml등)을 넣을 디렉토리
./users- 바인드 마운트
- 직접 만든 커스텀 사용자 파일(
dev-user.xml등)을 넣을 디렉토리
ClickHouse 내부 폴더 구조
/var/lib/clickhouse- ClickHouse의 고정된 데이터 저장 경로
/etc/clickhouse-server- config.xml - 모든 기본 설정을 담고 있는 메인 설정 파일
- users.xml - 모든 기본 사용자를 담고 있는 메인 사용자 파일
/etc/clickhouse-server/config.d- 직접 만든
./config폴더가 여기에 연결 custom.xml로 config.xml의 내용을 덮어쓰거나 추가
- 직접 만든
/etc/clickhouse-server/users.d- 직접 만든
./users폴더가 여기에 연결 dev-userxml.xml로 users.xml의 내용을 덮어쓰거나 추가
- 직접 만든
ClickHouse 기본 포트
8123(HTTP) - DBeaver 같은 GUI 툴, REST API 요청 등9000(Native TCP) - 성능이 가장 좋다. 클라이언트 연결용8443(HTTPS)9440(Secure Native TCP)
CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT: 1
1(켜기) 또는0(끄기)- 사용자의 권한과 비밀번호를 세밀하게 관리하는 기능을 활성화
ulimits 설정
- 동시에 열 수 있는 파일의 최대 개수를 늘려주는 옵션
- MergeTree 엔진에서 수백, 수천 개의 파일을 동시에 열어서 작업해야 하는데, 설정하지 않는다면 최대 개수를 낮게 설정하여 "Too many open files" 오류 발생
- 2의 18승으로 충분히 크고 안전하게 설정
컨테이너 구성 시작과 접속 확인
커스텀 config 설정
문서에서 “The default Clickhouse listen_host is 127.0.0.1”라는 언급
공식 Docker 이미지에서 아래를 설정한다.
<listen_host>0.0.0.0</listen_host> <!-- IPv4 모든 주소 -->clickhouse-dev/config/custom.xml생성<?xml version="1.0"?> <clickhouse> <listen_host>0.0.0.0</listen_host> </clickhouse>- 기본 접속은 localhost 접속이 허용되지만, Docker Container의 localhost와 로컬 PC의 localhost는 같지 않다.
- 이렇게 네트워크 바인딩을 설정해야 외부 접속이 가능하다.
ClickHouse 컨테이너 시작
docker-compose up -d- 상태 확인 :
docker-compose ps
- 상태 확인 :
ClickHouse 로그 확인
docker-compose logs clickhouse설정 파일 확인
- 파일 확인
docker exec clickhouse-server ls -la /etc/clickhouse-server/config.d/docker exec clickhouse-server cat /etc/clickhouse-server/config.d/test.xml
- 설정 적용 확인
docker exec clickhouse-server netstat -tln | grep 8123
- 파일 확인
연결 테스트
# 현재 버전 확인 curl -u admin:1234 'http://localhost:8123/?query=SELECT%20version()' # 현재 사용자 확인 curl -u admin:1234 'http://localhost:8123/?query=SELECT%20user()' # 데이터베이스 목록 curl -u admin:1234 'http://localhost:8123/?query=SHOW%20DATABASES' # 직접 접속 docker exec -it clickhouse-server clickhouse-client --user admin --password 1234- 브라우저 :
http://localhost:8123접속
- 브라우저 :
ClickHouse 연결 생성
새 연결 생성
연결 정보 설정
- Server Host : localhost
- Port : 8123
- Username : admin
- Password : 1234
- URL : jdbc:clickhouse://localhost:8123
Driver properties 탭에서 추가 설정
compress: true # 압축 활성화 max_execution_time: 300 # 쿼리 타임아웃 (초)compress: true- 네트워크 트래픽 압축으로 대용량 데이터 전송 시 속도 향상
max_execution_time: 300- 쿼리 타임 아웃으로 무한 대기 방지
연결 테스트
DBeaver에서 기본 쿼리 실행
버전 확인
SELECT version();데이터베이스 목록 확인
SHOW DATABASES;현재 사용자 정보
SELECT user(), currentDatabase();메모리 사용 정보 확인
SELECT (SELECT formatReadableSize(value) FROM system.asynchronous_metrics WHERE metric = 'MemoryResident') AS "프로세스 실제 사용량", (SELECT formatReadableSize(value) FROM system.asynchronous_metrics WHERE metric = 'TrackedMemory') AS "쿼리 사용량", (SELECT formatReadableSize(value) FROM system.asynchronous_metrics WHERE metric = 'CGroupMemoryUsed') AS "컨테이너 사용량", (SELECT formatReadableSize(value) FROM system.asynchronous_metrics WHERE metric = 'OSMemoryAvailable') AS "OS 여유 메모리" FROM system.one;
데이터베이스 생성
-- 의료 데이터 전용 데이터베이스 생성 CREATE DATABASE medical; -- 데이터베이스 사용 USE medical; -- 생성된 데이터베이스 확인 SHOW DATABASES;환자 기본정보 테이블
CREATE TABLE patients ( patient_id String, name String, birth_date Date, gender Enum8('M' = 1, 'F' = 2), phone String, email String, address String, registration_date DateTime DEFAULT now(), is_active UInt8 DEFAULT 1 ) ENGINE = MergeTree() ORDER BY patient_id PARTITION BY toYYYYMM(registration_date) COMMENT '환자 기본정보 테이블';테이블 설계 특징
patient_id: 환자 고유 식별자 (ORDER BY로 기본 정렬)Enum8: 성별을 숫자로 저장하여 압축 효율성 증대PARTITION BY: 등록월별 파티셔닝으로 쿼리 성능 향상MergeTree(): 압축 알고리즘 자동 적용
자동 압축의 원리
- ClickHouse의 MergeTree 계열 엔진은 데이터를 저장할 때, 서버 설정에 지정된 기본 압축 코덱(Default Codec)을 모든 컬럼에 자동으로 적용
- 이 기본 코덱은 일반적으로 압축 및 해제 속도가 매우 빠른 LZ4로 설정되어 있다.
진료기록 테이블
CREATE TABLE medical_records ( record_id String, patient_id String, visit_date DateTime, department String, doctor_name String, diagnosis_code String, -- ICD-10 코드 diagnosis_name String, symptoms Array(String), -- 증상 배열 treatment_plan Text, prescription Array(String), -- 처방약 배열 visit_type Enum8('OUTPATIENT' = 1, 'INPATIENT' = 2, 'EMERGENCY' = 3), cost Decimal(10,2), insurance_coverage Decimal(10,2), created_at DateTime DEFAULT now() ) ENGINE = MergeTree() ORDER BY (patient_id, visit_date) PARTITION BY toYYYYMM(visit_date) COMMENT '환자 진료기록 테이블';- Columnar DB 장점 활용
Array(String): 증상과 처방을 배열로 저장 (벡터화 처리 최적화)ORDER BY (patient_id, visit_date): 환자별 시계열 조회 최적화Decimal: 금액 데이터의 정확한 계산- 같은
PARTITION BY전략으로 날짜 범위 쿼리 효율화
- Columnar DB 장점 활용
샘플 데이터 INSERT
-- 환자 데이터 삽입 INSERT INTO patients VALUES ('P001', '김철수', '1985-03-15', 'M', '010-1234-5678', 'kim@email.com', '서울시 강남구', '2024-01-15 09:30:00', 1), ('P002', '이영희', '1990-07-22', 'F', '010-2345-6789', 'lee@email.com', '서울시 서초구', '2024-01-16 10:15:00', 1), ('P003', '박민수', '1978-11-08', 'M', '010-3456-7890', 'park@email.com', '경기도 성남시', '2024-01-17 14:20:00', 1), ('P004', '최지영', '1995-05-30', 'F', '010-4567-8901', 'choi@email.com', '서울시 송파구', '2024-02-01 11:45:00', 1), ('P005', '정대호', '1982-09-12', 'M', '010-5678-9012', 'jung@email.com', '인천시 남동구', '2024-02-03 16:30:00', 1); -- 진료기록 데이터 삽입 INSERT INTO medical_records VALUES ('R001', 'P001', '2024-02-01 09:00:00', '내과', '홍길동', 'K25.9', '위궤양', ['복통', '소화불량'], '약물치료 및 식단조절', ['오메프라졸', '돔페리돈'], 'OUTPATIENT', 45000.00, 31500.00, now()), ('R002', 'P002', '2024-02-01 14:30:00', '산부인과', '김영희', 'Z34.9', '임신관리', ['임신 증상'], '정기검진 및 영양제 복용', ['엽산', '철분제'], 'OUTPATIENT', 85000.00, 59500.00, now()), ('R003', 'P003', '2024-02-02 10:15:00', '정형외과', '박정수', 'M25.5', '관절통', ['무릎 통증', '부종'], '물리치료 및 진통제', ['이부프로펜', '근육이완제'], 'OUTPATIENT', 120000.00, 84000.00, now()), ('R004', 'P001', '2024-02-15 11:00:00', '내과', '홍길동', 'K25.9', '위궤양 추적관찰', ['호전된 상태'], '약물치료 지속', ['오메프라졸'], 'OUTPATIENT', 25000.00, 17500.00, now()), ('R005', 'P004', '2024-02-20 15:45:00', '응급의학과', '응급실의사', 'R50.9', '발열', ['고열', '오한', '두통'], '해열제 투여 및 관찰', ['아세트아미노펜'], 'EMERGENCY', 180000.00, 126000.00, now());
전체 환자 수 확인
SELECT COUNT(*) as total_patients FROM patients;- 결과
total_patients= 5
- 결과
성별 분포 확인
SELECT gender, COUNT(*) as count FROM patients GROUP BY gender;- 결과
gender count M 3 F 2
- 결과
월별 등록 환자 수
SELECT toYYYYMM(registration_date) as month, COUNT(*) as new_patients FROM patients GROUP BY month ORDER BY month;- ClickHouse 전용 함수
toYYYYMM()
- 결과
month new_patients 202401 3 202402 2
- ClickHouse 전용 함수
환자별 진료 이력 조회
SELECT p.name, mr.visit_date, mr.department, mr.diagnosis_name, mr.cost FROM patients p JOIN medical_records mr ON p.patient_id = mr.patient_id ORDER BY p.patient_id, mr.visit_date;- 결과
name visit_date department diagnosis_name cost 김철수 2024-02-01 09:00:00 내과 위궤양 45000.00 김철수 2024-02-15 11:00:00 내과 위궤양 추적관찰 25000.00 이영희 2024-02-01 14:30:00 산부인과 임신관리 85000.00 박민수 2024-02-02 10:15:00 정형외과 관절통 120000.00 최지영 2024-02-20 15:45:00 응급의학과 발열 180000.00
- 결과
부서별 매출 통계
SELECT department, COUNT(*) as visit_count, SUM(cost) as total_revenue, AVG(cost) as avg_cost, formatReadableSize(SUM(cost)) as readable_revenue FROM medical_records GROUP BY department ORDER BY total_revenue DESC;- ClickHouse 전용 함수
formatReadableSize()- 바이트를 KB/MB로 변환
- Columnar DB 집계의 장점은 속도
- 모든 행을 읽어서 필요한 컬럼만 추출하는 Row-based DB와 달리 필요한 컬럼만 바로 읽어서 계산한다.
- 결과
department visit_count total_revenue avg_cost readable_revenue 응급의학과 1 180000.00 180000.0 175.78 KiB 정형외과 1 120000.00 120000.0 117.19 KiB 산부인과 1 85000.00 85000.0 83.01 KiB 내과 2 70000.00 35000.0 68.36 KiB
- ClickHouse 전용 함수
배열 데이터 조회
SELECT patient_id, diagnosis_name, symptoms, arrayStringConcat(symptoms, ', ') as symptoms_text, length(prescription) as prescription_count FROM medical_records WHERE has(symptoms, '복통'); -- '복통' 증상이 있는 환자- ClickHouse 전용 함수
arrayStringConcat()- 배열 전용 함수has(symptoms, '복통')- 배열에서 특정 값 검색
- 결과
patient_id diagnosis_name symptoms symptoms_text prescription_count P001 위궤양 ['복통','소화불량'] 복통, 소화불량 2
- ClickHouse 전용 함수
ClickHouse의 MergeTree 엔진
- MergeTree 엔진은 데이터를 하나의 거대한 파일이 아닌, 여러 개의 작은 조각(Data Part)으로 나누어 저장한다.
INSERT를 할 때마다 새로운 데이터 파트가 생성되고, ClickHouse 백그라운드에서 이 작은 파트들을 더 큰 파트로 계속 병합하며 최적화한다.- system.parts 테이블은 모든 데이터 파트들의 목록과 상세 정보가 담겨있다.
Columnar DB 압축 효과 테스트
테이블 크기와 압축률 확인
SELECT table, formatReadableSize(sum(bytes_on_disk)) as compressed_size, formatReadableSize(sum(data_uncompressed_bytes)) as uncompressed_size, round(sum(data_uncompressed_bytes) / sum(bytes_on_disk), 2) as compression_ratio FROM system.parts WHERE database = 'medical' GROUP BY table;- medical 데이터베이스의 각 테이블이 디스크에서 얼마나 공간을 차지하는지, 압축률이 얼마나 되는지 보여준다.
- 동작 원리
FROM system.parts WHERE database = 'medical'- 모든 데이터 파트 목록 및 정보를 가져와서
medical만 필터링
- 모든 데이터 파트 목록 및 정보를 가져와서
GROUP BY tablepatients테이블용,medical_records테이블용으로 각각 그룹화
formatReadableSize()- Byte 단위의 숫자를
MiB,GiB처럼 사람이 읽기 쉬운 단위로 바꿔준다.
- Byte 단위의 숫자를
sum(bytes_on_disk)- 각 테이블 그룹별로 모든 데이터 파트를 압축 후 실제 크기를 합산
sum(data_uncompressed_bytes)- 각 테이블 그룹별로 모든 데이터 파트의 압축 전 원본 크기를 합산
compression_ratio(원본 크기 / 압축 후 크기)를 계산하여 압축률을 보여준다.
- 결과
table compressed_size uncompressed_size compression_ratio patients 2.30 KiB 358.00 B 0.15 medical_records 2.04 KiB 808.00 B 0.39 1.0보다 낮은 비는 원본보다 압축 후가 오히려 커졌음을 의미한다.- 이는 현재 데이터가 너무 적아서 발생하는 정상적인 현상
- ClickHouse가 데이터를 저장할 때는 데이터 자체뿐만 아니라 메타데이터, 체크섬 등 추가 정보가 담긴 데이터 파트를 만들기 때문
파티션별 데이터 분포 확인
SELECT partition, count() as parts_count, formatReadableSize(sum(bytes_on_disk)) as size_on_disk FROM system.parts WHERE database = 'medical' AND table = 'medical_records' GROUP BY partition ORDER BY partition;- 특정 테이블(
medical_records)의 데이터가 어떤 파티션에 얼마나 분포되어 있는지 보여준다. - 동작 원리
FROM system.parts WHERE ... table = 'medical_records'medical_records테이블에 속한 데이터 파트만 필터링
GROUP BY partition- 상자들을 우리가
PARTITION BY toYYYYMM(...)로 지정했던 파티션 키(202401,202402등)를 기준으로 그룹을 짓습니다.
- 상자들을 우리가
count() as parts_count- 각 파티션 그룹이 몇 개의 데이터 파트로 이루어져 있는지 카운트
- 카운트가 크면 현재 백그라운드 병합 작업이 완료되지 않음을 의미
- 단, 데이터 삽입이 없는데도 오랫동안 줄어들지 않는다면 문제가 될 수 있다.
sum(bytes_on_disk) as size_on_disk- 각 파티션 그룹이 디스크에서 차지하는 총 크기
- 결과
partition parts_count size_on_disk 202402 1 2.04 KiB 1이라는 것은 가장 이상적인 상태- 해당 파티션에 대한 모든 병합 작업이 완료되어 데이터가 완벽하게 최적화되었다는 뜻
- 특정 테이블(
Docker 사용 시 주의사항
Docker 환경에서는 컨테이너 재시작 시 데이터가 사라질 수 있다. docker-compose.yml에서 volumes 설정으로 데이터를 보존해야 한다.
docker-compose down
docker-compose up -d
성능 최적화 팁
로컬 개발 환경에서도 ClickHouse의 성능을 체험해보려면 메모리 설정을 적절히 조정해야 한다. 일반적으로 사용 가능한 RAM의 50-70% 정도를 ClickHouse에 할당하는 것이 좋다.
<max_server_memory_usage>8000000000</max_server_memory_usage> <!-- 8GB -->
상세 설명
MergeTree 엔진이란?
- ClickHouse의 기본이자 핵심 스토리지 엔진
- 대용량 데이터를 컬럼 기반으로 저장하고 사용자가 지정한 정렬 키(
ORDER BY)에 따라 자동 정렬하는 엔진 - 분석형 워크로드(OLAP)에 최적화된 설계
- 실시간 INSERT와 빠른 SELECT를 동시에 지원
MergeTree가 특별한 이유
- 가장 중요하고 가장 많이 사용되는 엔진
- 압축 알고리즘과 벡터화 처리가 모두 MergeTree에서 구현된다.
- 지속적인 백그라운드 최적화를 통해 쿼리 성능을 자동으로 향상시킨다
데이터 저장과 병합 원리
INSERT 시점 백그라운드 병합 후 ┌──────────────┐ ┌─────────────────┐ │ Part 1 │ │ │ │ (새 데이터) │ => 병합 => │ 최적화된 │ ├──────────────┤ │ 단일 Part │ │ Part 2 │ │ │ │ (새 데이터) │ └─────────────────┘ └──────────────┘- INSERT마다 새로운 데이터 Part 생성 ⇒ 작은 파일들이 많아진다.
- 백그라운드에서 자동 병합 ⇒ 큰 파일로 합쳐져 성능 향상
- 압축과 정렬 최적화 ⇒ 쿼리 속도 대폭 개선
왜 "MergeTree"라는 이름인가?
- Merge - 작은 데이터 조각들을 큰 조각으로 병합
- Tree - 정렬된 데이터 자체가 거대한 색인(인덱스) 역할을 하여, B-Tree처럼 빠르게 원하는 데이터 범위를 찾아갈 수 있다
- MySQL의 B-Tree 인덱스와 유사하지만, 전체 데이터가 정렬된 상태로 저장된다
MergeTree (기본형)
CREATE TABLE medical_analytics ( record_date Date, hospital_id String, patient_count UInt32, revenue Decimal(12,2), avg_stay_days Float32 ) ENGINE = MergeTree() ORDER BY (record_date, hospital_id) PARTITION BY toYYYYMM(record_date);특징
- 가장 기본적이고 범용적인 엔진
- 중복 데이터를 그대로 유지 (중복 제거 X)
- 시간순 append-only 데이터에 최적화
- 한 번 기록되면 수정되지 않는 데이터
- 시간 순서대로 계속 쌓이는 데이터
INSERT는 빠르고,UPDATE/DELETE는 비효율적- 예시 : 로그성 데이터, 이벤트 데이터
적합한 의료 데이터
- 환자 진료 기록 (각 방문마다 새 레코드)
- 과거 진료 기록은 수정되지 않는다 (법적 요구사항)
- 의료기기 센서 데이터 (시계열 로그)
- 센서 값은 한 번 측정되면 변경 불가
- 초/분 단위로 대량 데이터가 시간순 누적
- 수술/검사 이력 (변경되지 않는 팩트 데이터)
- 이미 완료된 의료 행위는 기록 변경 불가
- 환자 진료 기록 (각 방문마다 새 레코드)
ReplacingMergeTree (중복 제거)
CREATE TABLE patients_master ( patient_id String, name String, birth_date Date, phone String, address String, updated_at DateTime DEFAULT now() -- 버전 컬럼 (이름 자유) ) ENGINE = ReplacingMergeTree(updated_at) -- 버전 컬럼 지정 ORDER BY patient_id PARTITION BY toYear(birth_date);동작 원리
같은 ORDER BY 키를 가진 행들 중 최신 버전만 유지
버전 컬럼(
updated_at) 값이 가장 큰 행이 최종 버전비교 가능한(Comparable) 타입이면 모두 사용 가능
이름은 자유롭게 설정 가능
ReplacingMergeTree()로 버전 컬럼이 없다면 전체 행 비교(즉, 완전히 동일한 행만 제거)
백그라운드 병합 시점에 중복 제거 수행 (즉시 X)
적합한 의료 데이터
- 환자 마스터 정보 (연락처, 주소 변경 시 최신 버전만 필요)
- 환자 정보는 변경되지만 현재 정보만 중요 (중복 제거 필요)
- 자동으로 최신 버전만 유지
- 의료진 정보 (부서 이동, 직급 변경 등)
- 의사의 현재 소속 부서/직급만 필요 (과거 이력 불필요 ⇒ 자동 제거)
- 병원 정보 (주소, 연락처, 진료과목 변경)
- 병원의 현재 운영 정보만 필요 (자동 정리)
- 환자 마스터 정보 (연락처, 주소 변경 시 최신 버전만 필요)
주의사항
병합이 이루어지기 전에는 중복 데이터 존재
이때는
FINAL키워드로 쿼리해야 중복 제거된 결과 확인 가능❌ FINAL 없이 조회
SELECT * FROM patients_master WHERE patient_id = 'P001'; ---------------------------------------------------------- /* 결과: 3개 행이 모두 나옴 P001 | 김철수 | 010-1111-1111 | 2024-01-01 10:00:00 P001 | 김철수 | 010-2222-2222 | 2024-02-15 14:30:00 P001 | 김철수 | 010-3333-3333 | 2024-03-10 09:15:00 */
- 실시간으로 중복 제거되지 않는다
- 병합 전
- 중복된 여러 행이 존재 (FINAL 없으면 모두 조회된다)
- 병합 중
- 백그라운드에서 중복 제거 작업 진행
- 병합 후
- 물리적으로 최신 행만 남는다 (FINAL 없어도 1개만 조회된다)
- 병합 전
SummingMergeTree (사전 집계)
CREATE TABLE daily_hospital_stats ( stat_date Date, hospital_id String, department String, patient_count UInt32, -- 자동 합계 total_revenue Decimal(12,2), -- 자동 합계 avg_rating Float32 -- 합계되지 않음 (평균은 수동 계산 필요) ) ENGINE = SummingMergeTree((patient_count, total_revenue)) -- 합계할 컬럼 지정 ORDER BY (stat_date, hospital_id, department) PARTITION BY toYYYYMM(stat_date);동작 원리
- SummingMergeTree( )에 지정된 컬럼들(
patient_count,total_revenue)만 합계된다.- 단, ORDER BY에 있는 컬럼은 지정하면 안된다
- 반드시 숫자 타입 컬럼만 지정해야 한다.
- 지정하지 않는다면 모든 숫자 컬럼 자동 합계 (권장 X)
- 같은 ORDER BY 키를 가진 행들의 숫자 컬럼을 자동 합계 ⭐
- 미리 집계된 결과를 저장하여 쿼리 속도 극대화
ORDER BY가 동일한 데이터는 백그라운드 작업 시 하나의 데이터로 계속 집계되어 저장된다.
단, 백그라운드 작업 전에는 여러 데이터가 있지만, 작업 후에는 ORDER BY가 같다면 1개만 남는다.
(개별 데이터 보존 X)
INSERT할 때마다 바뀌는 게 아니라, 백그라운드에서 병합 시 집계 결과를 저장한다
- SummingMergeTree( )에 지정된 컬럼들(
적합한 의료 데이터
- 일별/월별 병원 통계 (환자 수, 매출, 수술 건수)
- 자동으로 같은 날짜 + 병원 + 부서의 데이터를 합계
- 병원 전체 합계를 별도 쿼리로 조회
- 부서별 KPI 지표 (진료 건수, 수익, 만족도)
- 자동으로 시간대별 데이터를 일별로 집계
- 매번 GROUP BY 계산 불필요
- 의료기기 사용량 집계 (시간당 사용률, 총 사용 시간)
- 기기별 누적 사용량을 자동으로 집계
- 사용할 때마다 증가하는 카운터성 데이터
- 일별/월별 병원 통계 (환자 수, 매출, 수술 건수)
장점
- 집계 쿼리가 극도로 빠름 (이미 계산된 값)
- 저장 공간 절약
- 여러 개의 원본 행들이 1개의 집계 행으로 합쳐진다
제한사항
- 평균값은 직접 계산 불가 (합계 ÷ 개수로 직접 계산)
- ORDER BY 키가 같은 데이터만 집계
- 유연한 집계 불가능
MySQL과의 차이점
항목 MySQL ClickHouse Primary Key 유일성 보장 필수 유일성 보장 안함 ORDER BY 데이터 정렬만 스토리지 구조 결정 인덱스 역할 B-Tree 인덱스 별도 ORDER BY가 인덱스 역할 중복 처리 중복 입력 시 오류 중복 허용 (엔진별로 다름) ClickHouse ORDER BY의 핵심 역할
CREATE TABLE patient_visits ( visit_date Date, patient_id String, hospital_id String, doctor_id String, diagnosis_code String ) ENGINE = MergeTree() ORDER BY (patient_id, visit_date);- ORDER BY (patient_id, visit_date)
- 이것이 스토리지 구조를 결정한다.
- 물리적 데이터 정렬
- 디스크에 실제로 이 순서로 저장된다
- 쿼리 성능 최적화
- ORDER BY와 동일한 순서로 조회 시 극도로 빠르다.
- 이미 정렬된 스토리지 구조에 따라 연속된 블록을 읽기 때문이다.
- 데이터 블록 건너뛰기
- ORDER BY 컬럼 : 물리적 정렬로 자동으로 데이터 블록 건너뛰기
- 기타 컬럼 : 스킵 인덱스 선언으로 블록 건너뛰기
- ORDER BY (patient_id, visit_date)
ORDER BY 설계가 중요한 이유
✅ 매우 빠른 쿼리
SELECT * FROM patient_visits WHERE patient_id = 'P001' AND visit_date >= '2024-01-01' ORDER BY patient_id, visit_date;- WHERE 절이 테이블 ORDER BY 순서와 일치하는 경우
- 연속된 데이터 블록을 읽기 때문에 쿼리가 매우 빠르다.
- WHERE 절의 첫 번째 조건이 테이블 ORDER BY의 첫 번째 컬럼과 일치
- 1순위 컬럼만 또는 1, 2순위 컬럼 순서대로
- WHERE 절이 테이블 ORDER BY 순서와 일치하는 경우
❌ 느린 쿼리
SELECT * FROM patient_visits WHERE doctor_id = 'D001' -- ORDER BY에 doctor_id가 없음 ORDER BY diagnosis_code; -- ORDER BY와 완전히 다른 정렬- WHERE 절이 테이블 ORDER BY와 다른 패턴
- ORDER BY에 없는 컬럼으로 필터링
- ORDER BY 순서를 건너뛰는 필터링
- WHERE 절이 테이블 ORDER BY와 다른 패턴
최적 ORDER BY 설계
쿼리 패턴 분석과 ORDER BY 결정
주요 쿼리 패턴 최적 ORDER BY 이유 환자별 시계열 조회 (patient_id, visit_date)환자 → 날짜 순 접근 병원별 일일 분석 (hospital_id, visit_date)병원 → 날짜 순 접근 진단별 통계 분석 (icd10_primary, visit_date)질병 → 날짜 순 접근 의사별 진료 현황 (doctor_id, visit_date)의사 → 날짜 순 접근 설계 우선순위
- 쿼리 빈도가 최우선 (가장 자주 사용되는 패턴)
- 카디널리티는 보조 고려사항 (동일한 중요도일 때)
- 최대 3-4개 컬럼까지만 사용 (너무 많으면 효과 감소)
- 실제 데이터 분포 확인해보기
ORDER BY 설계 예시
✅ 좋은 예 : 카디널리티 순서 고려
ORDER BY (hospital_id, department_code, visit_date, patient_id) -- 낮음(10개) 중간(50개) 높음(365일) 매우높음(10만명)❌ 나쁜 예 : 카디널리티 순서 잘못
ORDER BY (patient_id, hospital_id, department_code, visit_date) -- 매우높음 낮음 중간 높음
ClickHouse의 근본적 차이점
- ClickHouse 같은 분석 DB는 같은 이벤트가 여러 번 적재될 수 있음을 전제하기 때문에 Primary Key가 없고 중복 허용이 기본이다.
- 다른 분석 DB 중 하나인 Snowflake는 유일성 제약이 있다.
- MySQL과 같은 RDBMS는 Primary Key로 유일성 강제하고 중복 시 오류가 나타나기 때문에 Primary Key 레벨에서 유일성이 보장된다
- ClickHouse 같은 분석 DB는 같은 이벤트가 여러 번 적재될 수 있음을 전제하기 때문에 Primary Key가 없고 중복 허용이 기본이다.
중복 데이터 문제와 해결책
문제 상황
INSERT INTO patients_master VALUES ('P001', '김철수', '1985-03-15', ...); INSERT INTO patients_master VALUES ('P001', '김철수', '1985-03-15', ...); -- 중복!- 같은 환자 정보가 여러 번 입력된다. (데이터 중복)
해결책 1 : ReplacingMergeTree + FINAL
SELECT * FROM patients_master FINAL WHERE patient_id = 'P001';- ReplacingMergeTree로 중복 데이터를 백그라운드 작업으로 제거
- 백그라운드 병합 작업 전이여도 FINAL 키워드로 최신 버전만 조회
해결책 2 : GROUP BY로 중복 제거
SELECT patient_id, argMax(name, updated_at) as latest_name, argMax(phone, updated_at) as latest_phone FROM patients_master WHERE patient_id = 'P001' GROUP BY patient_id;- ReplacingMergeTree가 아닌 다른 엔진에서 중복을 제거하는 방법
- GROUP BY + argMax( )로 수동으로 최신 버전 선택
GROUP BY: 같은patient_id끼리 그룹화argMax(값, 기준): 기준이 최대인 행의 값을 선택P001 | 김철수 | 010-1111-1111 | 2024-01-01 10:00:00 P001 | 김철수 | 010-2222-2222 | 2024-02-15 14:30:00 -- updated_at이 가장 큼 P001 | 김철수 | 010-3333-3333 | 2024-01-10 09:15:00argMax(name, updated_at)→ "김철수"argMax(phone, updated_at)→ "010-2222-2222"
데이터 무결성 패턴
애플리케이션 레벨 중복 방지
삽입 전 존재 여부 확인
SELECT count() FROM patients_master WHERE patient_id = 'P001';존재하지 않을 때만 INSERT
INSERT INTO patients_master SELECT 'P001', '김철수', '1985-03-15', now() WHERE NOT EXISTS ( SELECT 1 FROM patients_master WHERE patient_id = 'P001' );- 이 패턴은 데이터 삽입이 동시에 발생할 확률이 낮은 환경이나 배치 작업에 유용
- 동시성이 높은 환경에서는 유일성을 보장하지 못할 수 있다.
- 동시에 여러 곳에서 데이터가 삽입될 경우, 두 개의 삽입 작업이 모두 존재하지 않음으로 판단할 수 있다.
고유 식별자 생성 패턴
UUID 활용한 유일성 보장
INSERT INTO medical_records VALUES ( generateUUIDv4(), 'P001', now(), -- ... 기타 컬럼들 );generateUUIDv4()- 고유한record_id자동 생성
타임스탬프 기반 복합 키
INSERT INTO sensor_data VALUES ( concat(device_id, '_', toString(toUnixTimestamp(now()))), device_id, now(), sensor_value );- 복합 유일키
concat(device_id, '_', toString(toUnixTimestamp(now())))
- 복합 유일키
환자 마스터 테이블 (ReplacingMergeTree)
CREATE TABLE patients_master ( patient_id String, name String, birth_date Date, gender Enum8('M' = 1, 'F' = 2), phone String, email String, address String, emergency_contact String, blood_type Enum8('A' = 1, 'B' = 2, 'AB' = 3, 'O' = 4), allergies Array(String), chronic_diseases Array(String), updated_at DateTime DEFAULT now(), is_active UInt8 DEFAULT 1 ) ENGINE = ReplacingMergeTree(updated_at) ORDER BY patient_id PARTITION BY toYear(birth_date) COMMENT '환자 마스터 정보 - 최신 버전만 유지';- 설계 특징
ReplacingMergeTree(updated_at)- 환자 정보 수정 시 최신 버전만 유지
ORDER BY patient_id- 환자별 빠른 조회를 위한 물리적 정렬 저장
PARTITION BY toYear(birth_date)- 파티션 전략으로 연령대별 데이터 분리
Array(String)- ClickHouse 배열 타입으로 알레르기, 만성질환 등 다중 값을 효율적으로 저장
- 설계 특징
진료 기록 테이블 (MergeTree)
CREATE TABLE medical_records ( record_id String, patient_id String, visit_date DateTime, hospital_id String, department_code String, doctor_id String, icd10_primary String, -- 주 진단코드 (ICD-10) icd10_secondary Array(String), -- 부 진단코드들 cpt_codes Array(String), -- 처치/수술 코드들 (CPT) symptoms Array(String), treatment_plan Text, prescription_drugs Array(String), visit_type Enum8('OUTPATIENT' = 1, 'INPATIENT' = 2, 'EMERGENCY' = 3), total_cost Decimal(10,2), insurance_coverage Decimal(10,2), created_at DateTime DEFAULT now() ) ENGINE = MergeTree() ORDER BY (patient_id, visit_date, hospital_id) PARTITION BY toYYYYMM(visit_date) COMMENT '환자 진료 기록 - 이력 데이터';설계 특징
MergeTree()- 진료 기록은 수정되지 않는 이력 데이터로 중복 허용
ORDER BY (patient_id, visit_date, hospital_id)- 환자별 시계열 조회에 최적화된 물리적 정렬
- 가장 빈번한 쿼리 패턴에 맞춘 순서 설계
PARTITION BY toYYYYMM(visit_date)- 월별 파티션으로 날짜 범위 쿼리 최적화
Enum8타입- 방문 유형 (외래/입원/응급)을 메모리 효율적으로 저장
Array(String)- 다중 진단/처치 코드를 효율적으로 저장
ICD-10/CPT 코드 체계 반영
- ICD-10 : 국제 질병 분류 코드 (
K25.9 = 위궤양) - CPT : 의료 처치/수술 코드 (
99213 = 외래 진료)
- ICD-10 : 국제 질병 분류 코드 (
ORDER BY 설계 의도
- 1순위 :
patient_id- 환자별 조회가 가장 빈번하니까
- 2순위 :
visit_date- 환자의 시계열 분석
- 이미 시간 순으로 정렬하여 추가 정렬 작업 불필요
- 3순위 :
hospital_id - 이렇게 하면 물리적으로 우선 순위에 따라 연속 저장된다
- 1순위 :
일별 통계 테이블 (SummingMergeTree)
CREATE TABLE daily_department_stats ( stat_date Date, hospital_id String, department_code String, -- 자동 합계될 컬럼들 outpatient_count UInt32, inpatient_count UInt32, emergency_count UInt32, total_revenue Decimal(12,2), total_patients UInt32, -- 수동 계산이 필요한 컬럼들 avg_cost_outpatient Decimal(10,2), avg_stay_days Float32, updated_at DateTime DEFAULT now() ) ENGINE = SummingMergeTree(( outpatient_count, inpatient_count, emergency_count, total_revenue, total_patients )) ORDER BY (stat_date, hospital_id, department_code) PARTITION BY toYYYYMM(stat_date) COMMENT '부서별 일간 통계 - 자동 집계';설계 특징
SummingMergeTree((outpatient_count, inpatient_count, ...))- 숫자 컬럼 자동 합계로 백그라운드 통계 집계
- 지정된 컬럼만 합계하여 의도치 않은 집계 방지
ORDER BY (stat_date, hospital_id, department_code)- 날짜별 ⇒ 병원별 ⇒ 부서별 계층적 집계 구조
- 자주 쓰이는 쿼리 패턴과 카디널리티 순서(낮음 → 높음)을 고려한다
PARTITION BY toYYYYMM(stat_date)- 월별 파티션으로 통계 조회 성능 향상
- 수동 계산 컬럼 분리
- 평균값 컬럼은 SummingMergeTree 대상에서 제외
- 쿼리 시
sum(total_revenue) / sum(total_patients)로 정확한 평균 계산
자동 집계 장점
- 쿼리 성능 극대화
- 매번
GROUP BY sum()을 계산할 필요 없다 - 이미 합계된 결과를 바로 조회 ⇒ 초고속 응답
- 매번
- 저장 공간 효율성
- 여러 개의 일별 데이터가 1개의 집계 데이터로 압축
- 원본 개별 기록 대신 합계 결과만 보관
- 대시보드 응답 최적화
- 월간/연간 통계 조회 시 즉시 응답 가능
- 복잡한 집계 연산 없이 단순 조회만으로 분석
- 쿼리 성능 극대화
평균값 계산 방법
SELECT hospital_id, department_code, sum(total_revenue) as total_revenue, sum(total_patients) as total_patients, if(sum(total_patients) > 0, sum(total_revenue) / sum(total_patients), 0) as avg_revenue_per_patient FROM daily_department_stats WHERE stat_date >= '2024-01-01' GROUP BY hospital_id, department_code ORDER BY avg_revenue_per_patient DESC;- 1단계
- SummingMergeTree가 일별 데이터를 자동 합계
- 2단계
- 쿼리에서
sum()으로 월간/연간 재집계
- 쿼리에서
- 3단계
총수익 ÷ 총환자수로 정확한 수동 평균 계산
if()함수로 0으로 나누기 방지
- 1단계
설계된 테이블을 활용한 JOIN 쿼리
환자별 진료 이력 종합 조회
SELECT p.name as patient_name, h.hospital_name, d.name as doctor_name, mr.visit_date, mr.icd10_primary, mr.total_cost FROM medical_records mr JOIN patients p FINAL ON mr.patient_id = p.patient_id JOIN hospitals h FINAL ON mr.hospital_id = h.hospital_id JOIN doctors d FINAL ON mr.doctor_id = d.doctor_id WHERE mr.patient_id = 'P001' ORDER BY mr.visit_date DESC;- FINAL로 최신 환자 정보만 사용
병원별 월간 성과 분석
SELECT toYYYYMM(ds.stat_date) as month, ds.hospital_id, sum(ds.total_revenue) as monthly_revenue, sum(ds.patient_count) as monthly_patients, if(monthly_patients > 0, monthly_revenue / monthly_patients, 0) as avg_revenue_per_patient FROM daily_stats ds WHERE ds.stat_date >= '2024-01-01' GROUP BY month, ds.hospital_id ORDER BY month, monthly_revenue DESC;
MergeTree 최적화 요소
ORDER BY 설계
- 가장 빈번한 쿼리 패턴에 맞춰 설계
- 카디널리티 낮은 컬럼부터 배치
- 3-4개 컬럼 이내로 제한
파티셔닝 전략
- 날짜 기반 파티셔닝 (월별 권장)
- 파티션당 적정 크기 유지 (1GB-10GB)
- 너무 작으면 ⇒ 파티션 관리 오버헤드 증가
- 너무 크면 ⇒ 쿼리 시 불필요한 데이터까지 스캔
- 쿼리에서 파티션 키 활용하기
압축 최적화
- 자주 조회되는 컬럼 : LZ4 (빠른 해제)
- 보관용 데이터 : ZSTD (높은 압축률)
- 타입별 최적 압축 코덱 선택
메모리 사용량 최적화 예시
-- 대용량 테이블 설정 예시 CREATE TABLE large_medical_data ( -- ... 컬럼 정의 ) ENGINE = MergeTree() ORDER BY (patient_id, visit_date) SETTINGS index_granularity = 8192, -- 기본값, 메모리 사용량 조절 merge_max_block_size = 8192, -- 병합 시 블록 크기 max_compress_block_size = 1048576, -- 압축 블록 크기 min_compress_block_size = 65536, -- 최소 압축 블록 크기 max_part_loading_threads = 4; -- 파트 로딩 스레드 수- 테이블 생성 시
SETTINGS구문을 통해 세부 동작을 직접 제어하여 메모리 사용량을 튜닝할 수 있다index_granularity(인덱스 간격)merge_max_block_size(병합 시 메모리 사용량) 등
- 테이블 생성 시
MergeTree 엔진 선택 가이드
데이터 특성 권장 엔진 사용 예시 변경되지 않는 이벤트 MergeTree 진료기록, 센서로그, 거래내역 마스터 데이터 ReplacingMergeTree 환자정보, 의료진정보, 병원정보 집계가 필요한 데이터 SummingMergeTree 일별통계, 부서별KPI, 매출집계 증분 집계 데이터 AggregatingMergeTree 실시간 대시보드, 복잡한 지표 - 테이블 생성 시
SETTINGS구문을 통해index_granularity(인덱스 간격),merge_max_block_size(병합 시 메모리 사용량) 등 세부 동작을 직접 제어하여 메모리 사용량을 튜닝할 수 있다
- 테이블 생성 시
실무에서 자주 하는 실수들
ORDER BY를 MySQL Primary Key처럼 사용
- 문제 : ClickHouse는 유일성 보장 X
- 해결 : 중복 데이터 처리 전략 필요
너무 많은 컬럼을 ORDER BY에 포함
- 문제 : 너무 많은 컬럼을 ORDER BY에 포함
- 해결 : 3-4개 컬럼 이내 권장
파티션을 너무 세밀하게 분할
- 문제 : 일별 파티션은 보통 과도하다
- 해결 : 월별 파티션이 일반적으로 최적
ReplacingMergeTree에서 FINAL 누락
-- ✅ 올바른 사용 SELECT * FROM patients_master FINAL WHERE patient_id = 'P001'; -- ❌ 잘못된 사용 SELECT * FROM patients_master WHERE patient_id = 'P001'; -- 중복 가능- 문제
- 백그라운드 병합 전에
FINAL없이는 중복 데이터가 조회된다.
- 백그라운드 병합 전에
- 해결
- 항상 FINAL 사용 (안전하지만 성능 저하)
- 또는 병합 상태 확인 후 사용 (복잡하지만 최적화)
- 문제
MergeTree 설계 핵심 원칙
- 쿼리 패턴 먼저 분석 ⇒ ORDER BY 설계
- 데이터 특성 파악 ⇒ 엔진 타입 선택
- 생명주기 고려 ⇒ TTL 설정
- 성능 모니터링 ⇒ 지속적 최적화
TTL (Time To Live) 기본 개념
- 자동 데이터 삭제 기능으로 법적 보관 기간 준수
- 의료법 준수
- 의료기록 보관 의무 기간 후 자동 삭제
- 개인정보보호법 준수
- 목적 달성 후 자동 파기
- 비용 절약
- 오래된 데이터는 저렴한 스토리지로 이동
의료 데이터 TTL 설정 예시
CREATE TABLE patient_records ( patient_id String, visit_date Date, personal_info String, medical_data Text, created_at DateTime DEFAULT now() ) ENGINE = MergeTree() ORDER BY (patient_id, visit_date) TTL created_at + INTERVAL 10 YEAR DELETE, -- 10년 후 전체 행 삭제 created_at + INTERVAL 3 YEAR TO DISK 'cold', -- 3년 후 저비용 스토리지로 이동 created_at + INTERVAL 1 YEAR GROUP BY patient_id -- 1년 후 환자별 집계 데이터로 변환 SET personal_info = '', -- 개인정보 삭제 medical_data = 'ARCHIVED' -- 의료정보 아카이브 처리- 단계별 데이터 생명주기
- 0-1년
- 전체 데이터 유지 (핫 스토리지)
- 1-3년
개인정보 삭제, 의료정보만 유지
created_at + INTERVAL 1 YEAR GROUP BY patient_id SET personal_info = '', medical_data = 'ARCHIVED'- 1년 후 환자별로 그룹화하면서 개인정보 삭제
- 개인정보 ⇒ 빈 문자열
- 의료정보 ⇒ "ARCHIVED"로 변경
- 1년 후 환자별로 그룹화하면서 개인정보 삭제
- 3-10년
- 콜드 스토리지로 이동 (비용 절약)
- TO DISK - 스토리지 이동
created_at + INTERVAL 3 YEAR TO DISK 'cold’- 3년 후 저비용 스토리지로 이동
- 10년 후
- DELETE - 완전 삭제
created_at + INTERVAL 10 YEAR DELETE- 10년 후 전체 행 삭제
- 0-1년
- 단계별 데이터 생명주기
실무적 TTL 활용 패턴
로그 데이터 자동 삭제
CREATE TABLE audit_logs ( log_date Date, user_id String, action String, details Text ) ENGINE = MergeTree() ORDER BY log_date TTL log_date + INTERVAL 7 YEAR DELETE; -- 감사 로그 7년 보관- 7년 후엔 법적으로 불필요 ⇒ 완전 삭제
임시 데이터 빠른 삭제
CREATE TABLE temp_analysis ( analysis_date Date, temp_data Text ) ENGINE = MergeTree() ORDER BY analysis_date TTL analysis_date + INTERVAL 30 DAY DELETE; -- 30일 후 자동 삭제- 30일 후엔 분석 가치 없음 ⇒ 빠른 정리
개인정보 마스킹
CREATE TABLE patient_analytics ( record_date Date, patient_id String, name String, diagnosis_code String ) ENGINE = MergeTree() ORDER BY record_date TTL record_date + INTERVAL 5 YEAR GROUP BY patient_id SET name = 'MASKED'; -- 5년 후 이름 마스킹- 5년 전 :
김철수 | 당뇨 | 서울시 강남구 - 5년 후 :
MASKED | 당뇨 | MASKED
- 5년 전 :
스킵 인덱스가 필요한 상황
ORDER BY에 없는 컬럼으로 검색 ⇒ 전체 스캔 발생
SELECT * FROM medical_records WHERE doctor_id = 'D001'; --doctor_id가 ORDER BY에 없어서 모든 블록을 다 확인해야 한다
문자열 부분 검색 ⇒ 전체 스캔 발생
SELECT * FROM medical_records WHERE patient_name LIKE '%김%';- "김"이 들어간 이름을 찾으려면 모든 환자 이름을 다 봐야 한다
범위가 넓은 숫자 검색 ⇒ 많은 블록 읽기
SELECT * FROM medical_records WHERE total_cost BETWEEN 50000 AND 200000;- 5만원~20만원 사이 진료비를 찾으려면 모든 비용 데이터를 확인해야 한다.
스킵 인덱스 설정
CREATE TABLE medical_records_optimized ( patient_id String, visit_date Date, doctor_id String, diagnosis_name String, patient_name String, total_cost Decimal(10,2), -- 스킵 인덱스들 INDEX idx_doctor doctor_id TYPE set(100) GRANULARITY 3, INDEX idx_name patient_name TYPE ngrambf_v1(4, 256, 2, 0) GRANULARITY 1, INDEX idx_cost total_cost TYPE minmax GRANULARITY 2, INDEX idx_diagnosis diagnosis_name TYPE bloom_filter() GRANULARITY 1 ) ENGINE = MergeTree() ORDER BY (patient_id, visit_date);- 각 인덱스 타입별 활용
set(100)- 의사 ID처럼 카디널리티가 낮은 값들에 사용
- 종류가 적은 데이터용
ngrambf_v1- 환자 이름 부분 검색(
LIKE '%김%')에 사용 - 이름을 작은 조각으로 나눠서 저장 ("김철수" → "김철", "철수")
- 환자 이름 부분 검색(
minmax- 비용처럼 숫자 범위 검색
- 각 블록의 최솟값/최댓값 저장한다.
bloom_filter- 진단명처럼 정확한 매칭 검색에 사용
- "위궤양"이라는 진단명이 있는지 빠르게 확인할 수 있다.
- 있으면 블록 확인, 없으면 건너뛰기
- 각 인덱스 타입별 활용
스킵 인덱스 효과 측정
인덱스 적용 전후 성능 비교
SELECT query, -- 어떤 쿼리인지 read_rows, -- 몇 개 행을 읽었는지 read_bytes, -- 몇 바이트를 읽었는지 query_duration_ms -- 얼마나 오래 걸렸는지 FROM system.query_log WHERE query LIKE '%medical_records%' AND event_time >= now() - INTERVAL 1 HOUR ORDER BY query_duration_ms DESC;특정 쿼리의 실행 계획 확인
EXPLAIN indexes = 1 SELECT * FROM medical_records_optimized WHERE doctor_id = 'D001';- 스킵 인덱스를 사용했는지, 몇 개 블록을 건너뛰었는지 알 수 있다.
성능 개선 지표
read_rows- 읽은 행 수 (적을수록 좋음)
read_bytes- 읽은 바이트 수 (적을수록 좋음)
query_duration_ms- 쿼리 실행 시간 (짧을수록 좋음)
상세 설명
ARRAY JOIN의 핵심 원리
MySQL에서는 JSON 배열을 처리하려면 복잡한 함수들을 써야 한다.
ClickHouse는 배열을 테이블의 행으로 펼치는 ARRAY JOIN을 제공한다.
-- 의료 기록에서 증상 배열을 개별 행으로 펼치기 SELECT patient_id, visit_date, diagnosis_name, symptom_item FROM medical_records ARRAY JOIN symptoms AS symptom_item WHERE patient_id = 'P001';ARRAY JOIN은 1개 행에 있던 배열의 요소들을 별도의 행로 펼쳐주는 기능이다.
결과
patient_id visit_date diagnosis_name symptom_item P001 2024-02-01 09:00:00 위궤양 복통 P001 2024-02-01 09:00:00 위궤양 소화불량
ARRAY JOIN 없이 조회 시
SELECT patient_id, visit_date, diagnosis_name, symptoms FROM medical_records WHERE patient_id = 'P001';결과
patient_id visit_date diagnosis_name symptoms P001 2024-02-01 09:00:00 위궤양 [’복통’, ’소화불량’]
하나의 테이블에 여러 배열이 있는 경우
CREATE TABLE medical_records_advanced ( record_id String, patient_id String, visit_date DateTime, symptoms Array(String), -- 증상 배열 icd10_codes Array(String), -- 진단코드 배열 prescription_drugs Array(String), -- 처방약 배열 lab_tests Array(String) -- 검사항목 배열 ) ENGINE = MergeTree() ORDER BY (patient_id, visit_date);여러 배열을 동시에 처리하는 패턴
-- 증상별 처방약 매핑 분석 SELECT symptom, groupArray(DISTINCT drug) AS related_drugs, count() AS frequency FROM medical_records_advanced ARRAY JOIN symptoms AS symptom, prescription_drugs AS drug GROUP BY symptom ORDER BY frequency DESC;원본 결과
patient_id symptoms prescription_drugs P001 ['복통', '소화불량'] ['제산제', '소화제'] P002 ['복통', '두통'] ['진통제', '위장약'] P003 ['소화불량'] ['소화제'] ARRAY JOIN 결과
patient_id symptom drug P001 복통 제산제 P001 소화불량 소화제 P002 복통 진통제 P002 두통 위장약 P003 소화불량 소화제 - 각 배열의 같은 인덱스에 있는 요소끼리 순서대로 묶여 새로운 행을 만든다.
- 즉, 각 배열의 첫 번째끼리 매칭, 이후 두 번째끼리 매칭된다.
groupArray( ) 결과
symptom related_drugs frequency 복통 ['제산제', '진통제'] 2 소화불량 ['소화제'] 2 두통 ['위장약'] 1 groupArray(지정컬럼)- ARRAY JOIN으로 펼친 행들을 다시 지정컬럼 기준 그룹별로 묶어 배열화하는 것A
DISTINCT drug: 모을 때 중복 제거groupArray(drug): 같은 그룹 안의 모든 약 다시 배열로 모은다.- 복통에는 ‘제산제’, ‘진통제’가 처방되었다.
주의사항
symptoms = ['복통', '소화불량', '속쓰림'] (3개) prescription_drugs = ['제산제', '소화제'] (2개) -- 결과: ('복통', '제산제'), ('소화불량', '소화제') 만 생성됨- 여러 배열을 ARRAY JOIN하면 각 배열의 첫 번째 요소끼리 묶이고, 다음으로 두 번째 요소끼리 묶여 순서대로 쌍으로 묶인다
- 만약 배열 길이가 다르면, 가장 짧은 배열 길이를 기준으로 처리되므로 주의해야 한다.
LEFT ARRAY JOIN으로 빈 배열 처리
-- 처방약이 없는 환자도 포함하여 조회 SELECT patient_id, diagnosis_name, coalesce(drug, 'No Prescription') AS prescription_status FROM medical_records_advanced LEFT ARRAY JOIN prescription_drugs AS drug WHERE visit_date >= '2024-02-01';- LEFT ARRAY JOIN으로 빈 배열 포함시키고,
coalescs()함수로 null 값 처리를 한다.
- LEFT ARRAY JOIN으로 빈 배열 포함시키고,
기존 JOIN 방식의 한계
-- ICD-10 코드 마스터 테이블 생성 CREATE TABLE icd10_master ( code String, korean_name String, english_name String, category String ) ENGINE = MergeTree() ORDER BY code; -- 샘플 데이터 INSERT INTO icd10_master VALUES ('K25.9', '위궤양, 상세불명', 'Gastric ulcer, unspecified', '소화기계'), ('K30', '기능성 소화불량', 'Functional dyspepsia', '소화기계'), ('J44.1', '급성 악화를 동반한 만성폐쇄성폐질환', 'COPD with acute exacerbation', '호흡기계'), ('J06.9', '급성 상기도감염, 상세불명', 'Acute upper respiratory infection', '호흡기계'), ('E11.9', '인슐린-비의존 당뇨병', 'Type 2 diabetes mellitus', '내분비계');진료 기록 테이블 (매일 수천~수만 건 발생)
record_id patient_id icd10_code visit_date cost R001 P001 K25.9 2024-01-01 50000 R002 P002 K30 2024-01-01 30000 R003 P003 J44.1 2024-01-01 80000 R004 P004 K25.9 2024-01-01 45000 … … ... … … ICD-10 코드 마스터 테이블 (거의 변경되지 않음)
code korean_name english_name category K25.9 위궤양, 상세불명 Gastric ulcer 소화기계 K30 기능성 소화불량 Functional dyspepsia 소화기계 J44.1 만성폐쇄성폐질환 COPD 호흡기계 E11.9 인슐린-비의존 당뇨병 Type 2 diabetes 내분비계
-- 진료비 통계 SELECT mr.patient_id, icd.korean_name AS diagnosis_korean, -- 한국어 병명이 필요 mr.cost, mr.visit_date FROM medical_records mr JOIN icd10_master icd ON mr.icd10_code = icd.code WHERE mr.visit_date >= '2024-01-01';- 진료비 통계를 조회할 때마다, 이런 쿼리를 날린다.
- JOIN 연산은 실행할 때마다 매번 디스크 I/O와 테이블 스캔이 발생하여, 수백만 건의 데이터에 대한 연산 비용이 발생
- 성능 비교
- JOIN 방식
- 디스크 읽기 → 테이블 스캔 → 매칭 → 결과 (수십ms)
- 딕셔너리 방식
- 메모리에서 키로 바로 조회 (수μs)
- JOIN 방식
딕셔너리(Dictionary)란
딕셔너리는 키-값 쌍으로 데이터를 저장하는 자료구조
ClickHouse 딕셔너리는 자주 참조하는 데이터를 메모리에 미리 로드해두고, 키로 값을 빠르게 조회할 수 있게 해주는 시스템
딕셔너리가 필요한 이유
- 딕셔너리의 핵심은 자주 참조하는 작은 테이블을 메모리에 올려두고, 키로 바로 찾는 것이다.
- 일반적인 JOIN은 매번 디스크를 읽어야 하지만, 딕셔너리는 메모리에 캐시되어 극도로 빠르다
딕셔너리 동작 방식
딕셔너리 로드 (서버 시작 시 1회)
- ClickHouse 메모리에 로드
딕셔너리["K25.9"] = { korean_name: "위궤양, 상세불명", english_name: "Gastric ulcer", category: "소화기계" } 딕셔너리["K30"] = { korean_name: "기능성 소화불량", english_name: "Functional dyspepsia", category: "소화기계" }
- ClickHouse 메모리에 로드
빠른 조회 (매 쿼리마다)
- JOIN 없이 메모리에서 키로 바로 조회
외부 딕셔너리 설정 파일
<?xml version="1.0"?> <dictionaries> <dictionary> <!-- 1. 딕셔너리 식별 정보 --> <name>icd10_dict</name> <!-- 딕셔너리 이름 (쿼리에서 사용) --> <!-- 2. 데이터 소스 설정 --> <source> <clickhouse> <host>localhost</host> <!-- ClickHouse 서버 주소 --> <port>9000</port> <!-- 포트 번호 --> <user>admin</user> <!-- 데이터베이스 유저명 --> <password>1234</password> <!-- 비밀번호 --> <db>medical</db> <!-- 데이터베이스명 --> <table>icd10_master</table> <!-- 소스 테이블명 --> </clickhouse> </source> <!-- 3. 메모리 저장 방식 --> <layout> <hashed /> <!-- 해시 테이블 방식 (O(1) 조회 속도) --> </layout> <!-- 4. 딕셔너리 구조 정의 --> <structure> <!-- 키(Key) 정의 --> <id> <name>code</name> <!-- icd10_master.code 컬럼을 키로 사용 --> </id> <!-- 값(Value) 정의 - 여러 개 가능 --> <attribute> <name>korean_name</name> <!-- 속성명 --> <type>String</type> <!-- 데이터 타입 --> </attribute> <attribute> <name>english_name</name> <type>String</type> </attribute> <attribute> <name>category</name> <type>String</type> </attribute> </structure> <!-- 5. 갱신 주기 --> <lifetime>300</lifetime> <!-- 300초(5분)마다 소스 테이블에서 다시 로드 --> </dictionary> </dictionaries>config/icd10_dictionary.xml파일 생성
외부 딕셔너리 설정 요소
<name>- 딕셔너리 식별자- 쿼리에서
dictGet()이 참조할 이름 - 여러 딕셔너리가 있을 때 구분하는 식별자
- 쿼리에서
<source>- 데이터 소스ClickHouse 테이블뿐만 아니라 MySQL, PostgreSQL, HTTP, CSV 등도 가능
외부 데이터베이스에서 데이터를 가져올 수도 있다
- MySQL에서 데이터 가져오기
<source> <mysql> <host>mysql-server.hospital.com</host> <!-- MySQL 서버 주소 --> <port>3306</port> <!-- MySQL 포트 --> <user>clickhouse_user</user> <!-- MySQL 유저명 --> <password>secure_password</password> <!-- MySQL 비밀번호 --> <db>hospital_db</db> <!-- MySQL 데이터베이스명 --> <table>icd10_codes</table> <!-- MySQL 테이블명 --> <!-- 선택사항: 커스텀 쿼리 --> <query> SELECT code, korean_name, english_name, category FROM icd10_codes WHERE is_active = 1 </query> </mysql> </source> - HTTP API에서 가져오기
<source> <http> <url>https://api.who.int/icd10/codes</url> <format>JSON</format> <headers> <header> <name>Authorization</name> <value>Bearer your-api-token</value> </header> </headers> </http> </source>
<layout>- 메모리 저장 방식<flat />: 배열 방식 (키가 연속 숫자일 때)<cache />: LRU 캐시 방식 (메모리 절약)<range_hashed />: 범위 검색용<hashed />: 해시 테이블: 빠른 조회, 많은 메모리
<structure>- 딕셔너리 구조- 키(id), 값(attribute) 설정
- attribute는 name(속성명)과 type(데이터 타입) 설정 필요
<lifetime>- 갱신 주기- 소스 테이블이 변경되면 딕셔너리도 자동 갱신
0으로 설정하면 서버 재시작할 때만 갱신
dictGet( ) 함수
dicGet( ) 사용 방법
dictGet('딕셔너리명', '속성명', 키값)SELECT patient_id, icd10_code, dictGet('icd10_dict', 'korean_name', icd10_code) AS korean_name FROM medical_records;동작 과정
medical_records에서icd10_code값("K25.9")을 읽는다- 메모리의 icd10_dict에서 키 "K25.9" 검색
- 해당 키의
korean_name속성 반환 ("위궤양, 상세불명")
여러 속성 조회
SELECT patient_id, dictGet('icd10_dict', 'korean_name', icd10_code) AS korean_name, dictGet('icd10_dict', 'category', icd10_code) AS category, dictGet('icd10_dict', 'english_name', icd10_code) AS english_name FROM medical_records;배열 내 모든 값 조회
SELECT patient_id, icd10_codes, -- ['K25.9', 'K30', 'J44.1'] arrayMap(x -> dictGet('icd10_dict', 'korean_name', x), icd10_codes) AS korean_names FROM medical_records_advanced;['K25.9', 'K30', 'J44.1']배열의 각 요소에 대해dictGet('icd10_dict', 'korean_name', x)실행- 결과를 새 배열로 조합 -
['위궤양, 상세불명', '기능성 소화불량', '만성폐쇄성폐질환']
dictGet( ) 함수 장점
- 속도
- 메모리에서 O(1) 조회
- 간편성
- JOIN 문법 없이 간단 조회
- 배열 지원
- arrayMap과 조합 가능
- NULL 처리
- 키가 없으면 기본값 반환
- 속도
WITH TOTALS로 집계와 소계 한 번에 처리
WITH TOTALS란
- 소계는 마지막에 전체 합계도 같이 보고 싶을 때 사용한다
MySQL에서는 소계를 구하려면 ROLLUP이나 별도 쿼리가 필요하다.
그러나, ClickHouse는
WITH TOTALS로 한 번에 처리한다기본 문법
SELECT 컬럼들... FROM 테이블 GROUP BY 컬럼 WITH TOTALS [ORDER BY ...]- GROUP BY와 함께 사용 - GROUP BY 없으면 의미 없다
- 집계 함수와 함께 사용 -
COUNT(),SUM(),AVG()등
동작 원리
- 일반적인 GROUP BY 실행
- 모든 그룹의 집계 함수 결과를 다시 집계
- "Totals" 행에 전체 합계 추가
사용 예시
-- 부서별 환자 수와 전체 소계 SELECT department, count() AS patient_count, sum(cost) AS total_revenue FROM medical_records GROUP BY department WITH TOTALS ORDER BY total_revenue DESC;- 결과 Totals :
department patient_count total_revenue 응급의학과 1 180000.00 정형외과 1 120000.00 산부인과 1 85000.00 내과 2 70000.00 department patient_count total_revenue - 5 455000.00 - 한 번의 쿼리로 그룹별 통계 + 전체 합계를 동시에 얻는다
- 결과
LIMIT BY로 그룹별 상위 N개 조회
LIMIT BY란
- 그룹별 상위 N개가 필요한 경우 사용한다
MySQL에서는 그룹별 상위 N개를 구하려면 복잡한 윈도우 함수가 필요하다.
그러나, ClickHouse는
LIMIT BY로 한 번에 처리한다기본 문법
SELECT 컬럼들... FROM 테이블 [WHERE 조건] ORDER BY 정렬기준 LIMIT N BY 그룹컬럼- ORDER BY 필수 - 정렬 없으면 어떤 N개를 가져올지 모른다
- LIMIT N BY 그룹 기준
- 그룹 기준은 어떤 컬럼으로 그룹을 나눌지
- N은 각 그룹에서 몇 개씩 가져올지
동작 원리
- ORDER BY로 정렬
- 그룹 컬럼별로 데이터 묶기
- 각 그룹에서 상위 N개씩만 선택
사용 예시
-- 각 환자별 최근 진료 기록 2개씩만 조회 SELECT patient_id, visit_date, diagnosis_name, cost FROM medical_records ORDER BY patient_id, visit_date DESC LIMIT 2 BY patient_id;- 결과
patient_id visit_date diagnosis cost P001 2024-02-01 위염 40000 P001 2024-01-15 두통 25000 P002 2024-02-10 완치 30000 P002 2024-01-20 재진 50000 - 각 그룹(
patient_id)별로 N개씩만 가져온다
- 각 그룹(
- 결과
FINAL 키워드와 중복 제거 완벽 이해
ReplacingMergeTree에서 FINAL의 필요성
앞서 학습한 ReplacingMergeTree는 백그라운드에서 중복을 제거하므로, 실시간으로는 중복된 데이터가 보일 수 있다
FINAL은 지금 당장 중복 제거해서 최신 데이터만 보는 명령어이다
- 데이터의 최종적인 정확성이 필요할 때 사용하는 핵심 키워드
기본 문법
SELECT 컬럼들... FROM 테이블명 FINAL [WHERE 조건]- 테이블명 바로 뒤 -
FROM table_name FINAL - ReplacingMergeTree에서만 의미 있음 - 다른 엔진에서는 효과 없음
- 성능 비용 - 실시간 중복 제거라서 느릴 수 있음
- 테이블명 바로 뒤 -
동작 원리
- 테이블에서 데이터 읽기
- 중복된 키 찾기
- 최신 버전만 남기고 나머지 제거
- 결과 반환
중복 입력 테스트
-- 환자 마스터 데이터 중복 입력 시뮬레이션 INSERT INTO patients_master VALUES ('P001', '김철수', '1985-03-15', 'M', '010-1111-1111', now()); INSERT INTO patients_master VALUES ('P001', '김철수(수정)', '1985-03-15', 'M', '010-2222-2222', now());FINAL 없이 조회 (중복 표시됨)
SELECT * FROM patients_master WHERE patient_id = 'P001';patient_id name phone updated_at P001 김철수 010-1111-1111 2024-01-01 10:00:00 P001 김철수(수정) 010-2222-2222 2024-01-01 11:00:00 - 아직 병합 전이라면, 수정 전 데이터까지 조회된다.
FINAL로 조회 (최신 버전만 표시)
SELECT * FROM patients_master FINAL WHERE patient_id = 'P001';patient_id name phone updated_at P001 김철수(수정) 010-2222-2222 2024-01-01 11:00:00
성능을 고려한 중복 제거 패턴
-- 방법 1: FINAL SELECT * FROM patients_master FINAL WHERE patient_id = 'P001'; -- 방법 2: GROUP BY SELECT patient_id, argMax(name, updated_at) AS latest_name, argMax(phone, updated_at) AS latest_phone, argMax(address, updated_at) AS latest_address, max(updated_at) AS last_updated FROM patients_master WHERE patient_id = 'P001' GROUP BY patient_id;FINAL은 편리하지만 테이블 전체를 스캔해서 중복을 제거하기에 메모리 사용량이 많아 성능 비용이 발생한다.- 그렇기 때문에 대용량 데이터나 성능이 중요한 경우
GROUP BY + argMax()를 사용하는 것이 더 좋을 수 있다
특화 구문 조합 활용
WITH TOTALS + LIMIT BY 조합
SELECT department, patient_id, cost, visit_date FROM medical_records ORDER BY department, cost DESC LIMIT 2 BY department WITH TOTALS;- 부서별 TOP 환자 + 전체 통계 조회
- 상위 선택 + 통계를 한 번에
ORDER BY department, cost DESC로 부서별로 묶고, 각 부서 내에서 비용 높은 순으로 정렬LIMIT 2 BY department로 각 부서별로 상위 2명씩만 선택WITH TOTALS로 선택된 데이터들의 전체 합계도 같이 표시
FINAL + LIMIT BY 조합
SELECT patient_id, name, phone, updated_at FROM patients_master FINAL ORDER BY patient_id, updated_at DESC LIMIT 1 BY patient_id;- 각 환자별 최신 정보만 조회
- 중복 제거 + 그룹별 선택을 한 번에
FINAL로 중복 제거해서 최신 데이터만 가져옴ORDER BY patient_id, updated_at DESC로 환자별로 묶고, 최신 순으로 정렬LIMIT 1 BY patient_id로 각 환자별로 최신 1개씩만 선택
핵심 배열 처리 함수
arraySort( )
arraySort(배열) -- 배열 요소를 정렬arraySlice( )
arraySlice(배열, 시작위치, 개수) -- 배열 일부만 처리- 배열이 너무 클 때 일부만 처리해서 메모리 절약
has( ) vs hasAny( )
has(배열, 값) -- 특정 값이 있는지 확인 hasAny(배열1, 배열2) -- 배열1에 배열2의 요소 중 하나라도 있는지- true / false 반환
arrayFilter( ) vs arrayMap( )
arrayFilter(x -> 조건, 배열) -- 조건에 맞는 요소만 필터링 arrayMap(x -> 변환식, 배열) -- 각 요소를 변환['복통', '감기', '호흡곤란']에서 심각한 증상만 →['호흡곤란']['타이레놀', '부루펜']→['타이레놀 200mg', '부루펜 200mg']
배열 처리 함수 예시
arraySort( ) 예시
SELECT arraySort(symptoms) AS symptom_combination, count() AS frequency, groupArray(DISTINCT patient_id) AS affected_patients FROM medical_records_advanced WHERE length(symptoms) >= 2 -- 2개 이상 증상이 있는 경우만 GROUP BY symptom_combination HAVING frequency >= 2 ORDER BY frequency DESC;증상 동시 발생 패턴 분석으로 어떤 증상들이 자주 같이 나타나는지 분석하는 쿼리
원본 데이터
patient_id symptoms P001 ['복통', '소화불량'] P002 ['복통', '두통'] P003 ['소화불량', '복통'] P004 ['감기'] P005 ['복통', '두통'] 동작 과정
- WHERE 필터링 - 2개 이상 증상이 있는 경우만 필터링
patient_id symptoms P001 ['복통', '소화불량'] P002 ['복통', '두통'] P003 ['소화불량', '복통'] P005 ['복통', '두통'] - P004 제외
arraySort()로 증상 배열 정렬patient_id symptoms P001 ['복통', '소화불량'] P002 ['두통', '복통'] P003 ['복통', '소화불량'] P005 ['두통', '복통'] - GROUP BY - 증상 배열 기준으로 그룹화
- 그룹 1
['복통', '소화불량']→ P001, P003
- 그룹 2
['두통', '복통']→ P002, P004
- 그룹 1
- 집계 함수 -
count() - 집계 함수 -
groupArray()- 각 그룹 안에 있는 환자 ID들을 배열로 모으기 위해 사용
['복통', '소화불량']그룹- P001, P003 ⇒
['P001', 'P003']
- P001, P003 ⇒
['두통', '복통']그룹- P002, P004 ⇒
['P002', 'P004']
- P002, P004 ⇒
- 각 그룹 안에 있는 환자 ID들을 배열로 모으기 위해 사용
- HAVING
symptom_combination frequency affected_patients ['복통', '소화불량'] 2 ['P001', 'P003'] ['두통', '복통'] 2 ['P002', 'P005']
- WHERE 필터링 - 2개 이상 증상이 있는 경우만 필터링
has( ), hasAny( ) 예시
SELECT patient_id, visit_date, prescription_drugs, CASE WHEN has(prescription_drugs, '와파린') AND hasAny(prescription_drugs, ['아스피린', '이부프로펜']) THEN '출혈 위험 - 상호작용 주의' ELSE '안전' END AS interaction_warning FROM medical_records_advanced WHERE length(prescription_drugs) >= 2;처방약 상호작용 위험 검사로 와파린과 함께 먹으면 위험한 약이 처방되었는지 확인하는 쿼리
원본 데이터
patient_id visit_date prescription_drugs P001 2024-01-01 ['타이레놀', '소화제'] P002 2024-01-02 ['와파린', '아스피린', '비타민'] P003 2024-01-03 ['와파린', '소화제'] P004 2024-01-04 ['이부프로펜'] P005 2024-01-05 ['와파린', '이부프로펜', '감기약'] P006 2024-01-06 ['타이레놀', '비타민'] 동작 과정
- WHERE 필터링 - 처방약이 2개 이상인 환자만 필터링
patient_id visit_date prescription_drugs P001 2024-01-01 ['타이레놀', '소화제'] P002 2024-01-02 ['와파린', '아스피린', '비타민'] P003 2024-01-03 ['와파린', '소화제'] P005 2024-01-05 ['와파린', '이부프로펜', '감기약'] P006 2024-01-06 ['타이레놀', '비타민'] - P004 제외
- CASE WHEN -
has(),hasAny()로 배열 검사- 와파린이 있는데 이부프로펜 or 아스피린까지 함께 있는지 체크
patient_id prescription_drugs 경고 메시지 P001 ['타이레놀', '소화제'] 안전 P002 ['와파린', '아스피린', '비타민'] 출혈 위험 - 상호작용 주의 P003 ['와파린', '소화제'] 안전 P005 ['와파린', '이부프로펜', '감기약'] 출혈 위험 - 상호작용 주의 P006 ['타이레놀', '비타민'] 안전
- WHERE 필터링 - 처방약이 2개 이상인 환자만 필터링
arrayFilter( ) 예시
SELECT patient_id, symptoms, arrayFilter(x -> x IN ('호흡곤란', '가슴통증', '의식저하', '고열'), symptoms) AS serious_symptoms FROM medical_records_advanced WHERE length(arrayFilter(x -> x IN ('호흡곤란', '가슴통증', '의식저하', '고열'), symptoms)) > 0;심각한 증상만 필터링으로 응급상황이 필요한 환자를 식별 하는 쿼리
원본 데이터
patient_id symptoms P001 ['복통', '소화불량', '어지러움'] P002 ['호흡곤란', '가슴통증', '두통'] P003 ['감기', '기침', '콧물'] P004 ['의식저하', '고열', '복통'] P005 ['두통', '목아픔'] P006 ['호흡곤란', '어지러움'] 동작 과정
arrayFilter()로 각 환자별로 심각한 증상만 추출- '호흡곤란', '가슴통증', '의식저하', '고열'
patient_id symptoms arrayFilter 결과 P001 ['복통', '소화불량', '어지러움'] [ ] P002 ['호흡곤란', '가슴통증', '두통'] ['호흡곤란', '가슴통증'] P003 ['감기', '기침', '콧물'] [ ] P004 ['의식저하', '고열', '복통'] ['의식저하', '고열'] P005 ['두통', '목아픔'] [ ] P006 ['호흡곤란', '어지러움'] ['호흡곤란'] - WHERE 필터링 - 심각한 증상이 1개 이상인 환자만
patient_id symptoms serious_symptoms P002 ['호흡곤란', '가슴통증', '두통'] ['호흡곤란', '가슴통증'] P004 ['의식저하', '고열', '복통'] ['의식저하', '고열'] P006 ['호흡곤란', '어지러움'] ['호흡곤란'] - P001, P003, P005 제외
arrayMap( ) 예시
SELECT patient_id, prescription_drugs, arrayMap(x -> concat(x, ' 200mg'), prescription_drugs) AS drugs_with_dosage FROM medical_records_advanced;약물 투여량 계산으로 모든 처방약에 표준 용량(200mg)을 자동 추가 하는 쿼리
원본 데이터
patient_id prescription_drugs P001 ['타이레놀', '소화제'] P002 ['와파린', '아스피린', '비타민'] P003 ['이부프로펜', '감기약'] P004 ['항생제'] P005 ['타이레놀', '소화제', '진통제'] 동작 과정
arrayMap()으로 각 약물명에 '200mg' 문자열 추가patient_id prescription_drugs drugs_with_dosage P001 ['타이레놀', '소화제'] ['타이레놀 200mg', '소화제 200mg'] P002 ['와파린', '아스피린', '비타민'] ['와파린 200mg', '아스피린 200mg', '비타민 200mg'] P003 ['이부프로펜', '감기약'] ['이부프로펜 200mg', '감기약 200mg'] P004 ['항생제'] ['항생제 200mg'] P005 ['타이레놀', '소화제', '진통제'] ['타이레놀 200mg', '소화제 200mg', '진통제 200mg']
기타 유용한 배열 처리 함수들
- arrayExists( )
arrayExists(x -> 조건, 배열) -- 조건 만족 요소 존재 여부 (true/false 반환)- 배열에 조건을 만족하는 요소가 하나라도 있는지 확인
arrayExists(x -> x = '복통', ['복통', '두통'])→true- 예시 : "위험한 증상이 하나라도 있나?" 체크할 때
- indexOf( )
indexOf(배열, 값) -- 요소의 위치 찾기 (1부터 시작, 없으면 0)- 배열에서 특정 값의 첫 번째 위치를 반환
indexOf(['복통', '두통', '복통'], '두통')→2- 예시 : "특정 약물이 처방 순서상 몇 번째인가?" 확인할 때
- arrayCount( )
arrayCount(x -> 조건, 배열) -- 조건 만족 요소 개수- 배열에서 조건을 만족하는 요소의 개수를 세기
arrayCount(x -> length(x) > 2, ['복통', '두통', '소화불량'])→2(복통, 소화불량)- 예시 : "심각한 증상이 몇 개나 되나?" 셀 때
- arrayDistinct( )
arrayDistinct(배열) -- 중복 제거된 배열 반환- 배열에서 중복을 제거하고 고유한 요소들만 반환
arrayDistinct(['복통', '두통', '복통'])→['복통', '두통']- 예시 : "중복된 진단코드 제거" 할 때
- arrayUniq( )
arrayUniq(배열) -- 고유 요소 개수- 배열에서 중복을 제거한 후의 개수를 반환
arrayUniq(['복통', '두통', '복통'])→2- 예시 : "환자가 앓은 고유 질병 수" 셀 때
- arrayReduce( )
arrayReduce(집계함수, 배열) -- 배열에 집계함수 적용- 배열의 모든 요소에 집계 함수를 적용
arrayReduce('sum', [10, 20, 30])→60arrayReduce('avg', [10, 20, 30])→20- 예시 : "배열 내 수치들의 합계/평균" 구할 때
- arrayExists( )
실무 팁과 성능 최적화
효율적인 쿼리 작성 패턴
❌ 비효율적 : 큰 배열을 매번 JOIN
SELECT count() FROM medical_records mr ARRAY JOIN symptoms AS symptom WHERE symptom = '복통';- 문제점
- 메모리 사용량 증가 - 모든 증상을 개별 행으로 펼친다
- 불필요한 데이터 생성 - "복통" 하나 찾으려고 전체 배열 펼치기
- 문제점
✅ 효율적 : has( ) 함수 사용
SELECT count() FROM medical_records WHERE has(symptoms, '복통');- 장점
- 메모리 절약 - 배열을 펼치지 않고 바로 검색
- 빠른 처리 - O(n) 배열 스캔으로 즉시 판정
- 간단한 로직 - 복잡한 JOIN 없이 한 번에 처리
- ARRAY JOIN 방식 대비 5-10배 빠르다
- 장점
❌ 비효율적 : 딕셔너리 없는 반복 JOIN
SELECT mr.*, icd.korean_name FROM medical_records mr JOIN icd10_master icd ON mr.icd10_primary = icd.code;- 문제점
- 디스크 I/O 반복 - 매번 테이블을 디스크에서 읽는다
- JOIN 연산 비용 - 해시 테이블 생성 + 매칭 과정 반복
- 캐시 비효율 - 같은 코드를 수백 번 조회해도 매번 JOIN
- 문제점
✅ 효율적 : 딕셔너리 활용
SELECT *, dictGet('icd10_dict', 'korean_name', icd10_primary) AS korean_name FROM medical_records;- 장점
- 메모리 캐시 - 딕셔너리가 메모리에 존재
- O(1) 조회 - 해시 테이블로 즉시 검색
- 중복 제거 - 같은 코드 재조회 시 캐시에서 바로 반환
- JOIN 방식 대비 10-50배 빠르다
- 장점
메모리 사용량 최적화
대용량 배열 처리 시 메모리 절약
SELECT patient_id, arraySlice(symptoms, 1, 3) AS top_symptoms -- 상위 3개만 처리 FROM medical_records_advanced WHERE length(symptoms) > 10;- 환자별로 증상이 많을 때 (10개 이상)
arraySlice()함수 활용- 배열의 일부분만 추출하여 메모리 절약
- 활용 시나리오
- 환자별 주요 증상 TOP 3만 분석
- 처방약 중 핵심 약물만 체크
- 검사 결과 중 이상치만 확인
스트리밍 방식으로 큰 결과셋 처리
SELECT * FROM medical_records ORDER BY visit_date LIMIT 1000000 SETTINGS max_memory_usage = 1000000000; -- 1GB 제한- 대용량 데이터 조회 시 메모리 부족 방지
- SETTINGS 옵션 설명
- max_memory_usage - 쿼리 실행 시 최대 메모리 사용량 제한
- 1000000000 - 1GB (1,000,000,000 bytes)
- 효과 - 메모리 한계 도달 시 자동으로 디스크 사용
- 동작 방식
- 메모리에서 처리 (빠름)
- 메모리 1GB 도달 시
- 임시 파일로 스왑 (느리지만 안전)
- 스트리밍으로 결과 반환
ClickHouse SQL 핵심 요약
기능 사용 시점 성능 효과 ARRAY JOIN 배열을 행으로 펼칠 때 복잡한 배열 분석 가능 dictGet() 마스터 데이터 테이블 빈번 조회 JOIN 대비 10-50배 빠름 WITH TOTALS 소계가 필요한 리포트 별도 쿼리 불필요 LIMIT BY 각 그룹별 상위 N개만 필요할 때 데이터량 대폭 감소 FINAL ReplacingMergeTree에서 최신 데이터만 필요할 때 중복 제거 보장 실무에서 자주 하는 실수들
불필요한 ARRAY JOIN 남발
has(),arrayExists()함수로 대체 가능한 경우가 많다.- 판별 기준은 "배열 요소별 상세 분석"이 아니라 "존재 여부만 확인"이면
has()계열 사용하는 것이 좋다
FINAL을 모든 쿼리에 사용
- 성능 저하 원인, 정말 필요한 경우만 사용
딕셔너리 설정 없이 반복 JOIN
- 자주 조회하는 마스터 테이블은 반드시 딕셔너리로 구성
- 기준
- 조회 빈도 >100회/시간 → 딕셔너리 필수
- 조회 빈도 >마스터 테이블 크기 < 10만 건 → 딕셔너리 적합
- 변경 빈도 < 1회/일 → 딕셔너리 적합
- 예시
- ICD-10 진단코드
- 약품 마스터
- 부서/지역 코드
- 고객 등급 코드
최적화 팁
- "찾기"가 목적이면 →
has(),hasAny(),arrayExists()계열 함수 사용 - "변환"이 목적이면 →
dictGet()또는arrayMap()활용 - "분석"이 목적이면 →
ARRAY JOIN+ 집계 함수 조합 - 자주 쓰는 마스터 테이블 → 반드시 딕셔너리로 구성 (조회 빈도 > 100회/시간)
- 배열 크기 > 10개 →
arraySlice()로 메모리 사용량 주의 - 대용량 결과셋 →
SETTINGS max_memory_usage제한 설정 - ReplacingMergeTree → 정말 필요한 경우만
FINAL사용 - 마스터 테이블 크기 < 10만 건 → 딕셔너리 최적화 대상
- "찾기"가 목적이면 →
상세 설명
분산 시스템의 핵심 - ZooKeeper (ZK)
ZooKeeper는 분산 시스템의 메타데이터와 설정 정보를 중앙에서 관리하는 서비스이다.
ClickHouse 클러스터에서 ZooKeeper 역할
복제 테이블 메타데이터 관리
ReplicatedMergeTree테이블의 모든 메타데이터를 중앙 저장소에 보관- 각 데이터 파티션이 어떤 노드에 있는지 실시간 추적
- 클러스터에 속한 모든 노드의 구성 정보와 상태 관리
- 노드가 추가/제거될 때 클러스터 토폴로지 자동 업데이트
데이터 복제 조정 (Replication Coordination)
ReplicatedMergeTree에서 새 데이터 INSERT 시 모든 레플리카에 복제 지시- 각 레플리카의 복제 진행 상황과 지연(lag) 모니터링
- 복제 실패 시 재시도 큐(queue) 관리
- 노드 장애 시 다른 레플리카로 자동 페일오버
분산 DDL 동기화
ON CLUSTER명령어 실행 시 모든 노드에 순차적/병렬 실행 조정- CREATE/ALTER/DROP TABLE 같은 스키마 변경사항 동기화
- DDL 실행 성공/실패 상태를 추적하고 롤백 관리
- 예시 :
CREATE TABLE ON CLUSTER my_cluster는 ZooKeeper를 통해 모든 노드에 전파
분산 작업 충돌 방지와 리더 선출
- 백그라운드 Merge 작업을 수행할 리더 노드 선출
- 동일한 파티션에 대한 동시 작업 방지 (분산 락)
- 여러 노드가 동시에 같은 데이터를 수정하려 할 때 순서 보장
- Part 이동, 파티션 드롭 등 위험한 작업의 원자성 보장
클러스터 상태 모니터링과 헬스체크
- 각 노드의 생존 상태를 주기적으로 체크 (하트비트)
- 노드 다운 감지 시 클러스터에서 자동 제외
- 복구된 노드의 클러스터 재진입 관리
- 쿼럼(Quorum) 기반 의사결정으로 스플릿 브레인 방지
최신 트렌드 : ClickHouse Keeper
2022년부터 C++로 작성된 ClickHouse Keeper가 production-ready가 되었다
주요 개선사항
- C++로 작성되어 ClickHouse와 네이티브 통합되어 신규 구축 시 Keeper 사용을 권장한다.
- 메모리 사용량 46배 감소, I/O 8배 개선
- ZooKeeper와 프로토콜 호환 (설정만 바꾸면 전환 가능)
- Java GC 문제 완전 해결
현재 상황
- ClickHouse Cloud는 모두 Keeper 사용
- 신규 온프레미스 구축도 Keeper 권장
- 기존 ZooKeeper 사용자는 설정 파일만 변경하면 전환 가능
데이터 분산의 두 축 - 샤드와 레플리카
샤드(Shard) - 수평 분할
- 데이터를 여러 서버에 나누어 저장
- 각 샤드는 전체 데이터의 일부분만 저장 ⇒ 전체 데이터셋을 나누어 저장
- 샤드 수를 늘리면 저장 용량과 처리 성능이 선형적으로 증가
- 목적 : 데이터 양이 너무 많아 한 서버에 다 못 담거나, 병렬 처리로 성능 향상
- 예:
- 회원 ID 1~1,000,000 → Shard 1
- 회원 ID 1,000,001~2,000,000 → Shard 2
레플리카(Replica) - 복제본
- 같은 샤드의 모든 레플리카는 완전히 동일한 데이터 보유
- 한 레플리카가 다운되어도 서비스 중단 없음 (High Availability)
- 읽기 요청을 여러 레플리카로 부하 분산 가능
- 쓰기는 모든 레플리카에 전파되어야 하므로 쓰기 성능은 향상되지 않음
- 목적 : 장애 복구(HA) + 읽기 부하 분산
ClickHouse 샤드 & 리플리카 구조 예시
의료 데이터 클러스터 (환자 1억 명, 진료기록 10억 건) │ ├─ Shard 1 (환자 1~3,300만) │ ├─ Replica 1 [서버 A] - 마스터 역할 │ ├─ Replica 2 [서버 B] - 읽기 전용 │ └─ Replica 3 [서버 C] - 백업/재해복구용 │ ├─ Shard 2 (환자 3,300만~6,600만) │ ├─ Replica 1 [서버 D] │ ├─ Replica 2 [서버 E] │ └─ Replica 3 [서버 F] │ └─ Shard 3 (환자 6,600만~1억) ├─ Replica 1 [서버 G] ├─ Replica 2 [서버 H] └─ Replica 3 [서버 I] 총 9대 서버 = 3 샤드 × 3 레플리카- 샤드와 레플리카 수 결정 기준
- 샤드 수 = 데이터 총량 ÷ 서버당 저장 가능 용량
- 1TB 데이터, 서버당 200GB 가능 ⇒ 최소 5개 샤드 필요
- 레플리카 수 = 가용성 요구사항 + 읽기 부하
- 일반 서비스 : 2개 (마스터 + 백업)
- 중요 서비스 : 3개 (과반수 쿼럼 확보)
- 읽기 많은 서비스 : 4개 이상
- 샤드 수 = 데이터 총량 ÷ 서버당 저장 가능 용량
- 샤드와 레플리카 수 결정 기준
샤드(Shard) vs 파티션(Partition) 차이
구분 샤드(Shard) 파티션(Partition) 개념 데이터를 여러 서버에 분산 데이터를 한 서버 내에서 분할 위치 물리적으로 다른 서버/노드 같은 서버의 다른 디렉토리/파일 목적 수평 확장(Scale-out) 쿼리 최적화, 데이터 관리 확장성 서버 추가로 무한 확장 가능 단일 서버 용량에 제한 장애 영향 샤드 하나 다운 시 일부 데이터만 영향 서버 다운 시 모든 파티션 영향 ClickHouse 예시 Distributed테이블로 구현PARTITION BY toYYYYMM(date)
클러스터 아키텍처 설계
실무에서는 수십 대의 서버로 클러스터를 구성하는 경우도 있다
개발 환경에서 Docker Compose로 최소 구성을 만들어 동작 원리를 학습하는 것이 이번 장의 목적이다
docker-compose-cluster.yml
version: '3.8' services: # ZooKeeper - 클러스터 메타데이터 관리 zookeeper: image: confluentinc/cp-zookeeper:latest hostname: zookeeper container_name: zookeeper ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 volumes: - zk-data:/var/lib/zookeeper/data - zk-logs:/var/lib/zookeeper/log # ClickHouse 노드 1 clickhouse-01: image: clickhouse/clickhouse-server:latest hostname: clickhouse-01 container_name: clickhouse-01 ports: - "8123:8123" - "9000:9000" volumes: - ch01-data:/var/lib/clickhouse - ./cluster-config/clickhouse-01:/etc/clickhouse-server/config.d - ./cluster-config/users:/etc/clickhouse-server/users.d depends_on: - zookeeper ulimits: nofile: soft: 262144 hard: 262144 # ClickHouse 노드 2 clickhouse-02: image: clickhouse/clickhouse-server:latest hostname: clickhouse-02 container_name: clickhouse-02 ports: - "8124:8123" - "9001:9000" volumes: - ./cluster-config/clickhouse-02:/etc/clickhouse-server/config.d - ./cluster-config/users:/etc/clickhouse-server/users.d - ch02-data:/var/lib/clickhouse depends_on: - zookeeper ulimits: nofile: soft: 262144 hard: 262144 volumes: zk-data: zk-logs: ch01-data: ch02-data:zookeeper 설정 상세 설명
zookeeper: image: confluentinc/cp-zookeeper:latest hostname: zookeeper container_name: zookeeper ports: - "2181:2181" environment: ZOOKEEPER_CLIENT_PORT: 2181 ZOOKEEPER_TICK_TIME: 2000 volumes: - zk-data:/var/lib/zookeeper/data - zk-logs:/var/lib/zookeeper/log- image: confluentinc/cp-zookeeper:latest
- Kafka를 개발한 Confluent에서 제공하는 안정화된 ZooKeeper 이미지
- 포트 : 2181
- ZooKeeper 기본 클라이언트 포트
- environment
ZOOKEEPER_CLIENT_PORT: 2181 # 클라이언트 연결 포트 ZOOKEEPER_TICK_TIME: 2000 # 기본 시간 단위 (밀리초)- 기본 시간 단위 : 2초
- 하트비트, 타임아웃, 세션 관리의 기준 시간
- 세션 타임아웃이 6 tick이면 12초 (2000ms × 6)
- Session Timeout : 기본적으로 6 tick
- Connection Timeout : 기본적으로 2 tick
- Sync Limit : 기본적으로 5 tick
tick: ZooKeeper의 기본 시간 단위
- volumes (데이터 영속화)
volumes: - zk-data:/var/lib/zookeeper/data # 클러스터 메타데이터 저장 - zk-logs:/var/lib/zookeeper/log # 트랜잭션 로그 저장- 데이터 유실 방지
- 메타데이터 보관
- image: confluentinc/cp-zookeeper:latest
각 노드 설정
- 각 노드의 포트 설정
clickhouse-01: ... ports: - "8123:8123" # HTTP 포트 - "9000:9000" # TCP 포트 clickhouse-02: ... ports: - "8124:8123" - "9001:9000" - depends_on 설정
depends_on: - zookeeper # ZooKeeper가 먼저 시작되어야 한다- 시작 순서 제어
- ZooKeeper → ClickHouse 노드 순서로 시작
- 의존성
- ClickHouse가 ZooKeeper 없이는 동작할 수 없음을 명시
- 시작 순서 제어
- 각 노드의 포트 설정
샤드와 레플리카 설정 구성
cluster-config/clickhouse-01/cluster.xml
<?xml version="1.0"?> <clickhouse> <!-- 클러스터 정의 --> <remote_servers> <medical_cluster> <shard> <replica> <host>clickhouse-01</host> <port>9000</port> <user>admin</user> <password>1234</password> </replica> <replica> <host>clickhouse-02</host> <port>9000</port> <user>admin</user> <password>1234</password> </replica> </shard> </medical_cluster> </remote_servers> <!-- ZooKeeper 설정 --> <zookeeper> <node> <host>zookeeper</host> <port>2181</port> </node> </zookeeper> <!-- 매크로 설정 (각 노드별로 다름) --> <macros> <cluster>medical_cluster</cluster> <shard>01</shard> <replica>clickhouse-01</replica> </macros> <!-- 네트워크 설정 --> <listen_host>0.0.0.0</listen_host> <http_port>8123</http_port> <tcp_port>9000</tcp_port> </clickhouse>클러스터 설정과 ZooKeeper 설정
medical_cluster └── shard 1 ├── replica 1 (clickhouse-01) ← 같은 데이터 └── replica 2 (clickhouse-02) ← 같은 데이터 (백업)클러스터 연결 설정
<remote_servers> <medical_cluster> <shard> <replica> <host>clickhouse-01</host> <port>9000</port> <user>admin</user> <password>1234</password> </replica> <replica> <host>clickhouse-02</host> <port>9000</port> <user>admin</user> <password>1234</password> </replica> </shard> </medical_cluster> </remote_servers>클러스터 통신은 TCP만 사용 (노드간 통신)
- 데이터 복제 (Binary 프로토콜 필요)
- 메타데이터 동기화 (고성능 필요)
- 클러스터 상태 체크 (실시간성 필요)
- 분산 쿼리 실행 (최적화된 프로토콜 필요)
HTTP는 부적합한 이유
- 오버헤드
- TCP 대비 느림
- 바이너리 데이터 전송 어려움
실제 통신 시나리오
사용자 → localhost:8124 (HTTP) → clickhouse-02:8123 → ClickHouse HTTP 서버 사용자 → localhost:9001 (TCP) → clickhouse-02:9000 → ClickHouse TCP 서버 clickhouse-01 → clickhouse-02:9000 (TCP) → ClickHouse TCP 서버
ZooKeeper 연결 설정
<zookeeper> <node> <host>zookeeper</host> <port>2181</port> </node> </zookeeper>- 메타데이터 저장소, 리더 선출, 장애 감지
매크로 설정 (노드별 고유값)
<macros> <cluster>medical_cluster</cluster> <shard>01</shard> <replica>clickhouse-01</replica> </macros>
클러스터 네트워크 구성과 포트 설정
listen_host: 0.0.0.0: 모든 IP에서 접속 허용 (컨테이너 환경에서 필수)<http_port>8123</http_port>: HTTP 포트 (DBeaver, API 접근)<tcp_port>9000</tcp_port>: Native TCP 포트 (노드간 통신, 고성능)<replica> <host>clickhouse-01</host> <port>9000</port> </replica>- 2개의 포트가 일치하지 않으면 연결 실패 !
- 클러스터 필수 (노드 간 통신)
2181: ZooKeeper 포트 (메타데이터 동기화)
포트 3층 구조
외부 접근 포트 → Docker 매핑 → ClickHouse 내부 포트
9001 → 9000 → 9000
외부 접근 포트 : 9001
- 역할
- 호스트 머신에서 컨테이너로 들어가는 관문
- 사용자
- 외부 클라이언트, 개발자
- 예시
clickhouse-client --host localhost --port 9001
- 역할
Docker 컨테이너 포트 : 9000
- 역할
- Docker 네트워크 내부에서 컨테이너가 받는 포트
- 사용자
- Docker 네트워크, 다른 컨테이너
- 예시
- 컨테이너 간 통신 시
clickhouse-02:9000
- 컨테이너 간 통신 시
- 역할
ClickHouse 애플리케이션 포트 : 9000
- 역할
- ClickHouse 서버가 실제로 리스닝하는 포트
- 설정
<tcp_port>9000</tcp_port>
- 사용자
- ClickHouse 프로세스 자체
- 역할
매크로란 무엇인가?
매크로는 변수 같은 개념으로, SQL 실행 시점에 실제 값으로 대체된다.
매크로 사용 이유
매크로 없이 하면 각 노드마다 다른 SQL 작성해야 한다.
-- clickhouse-01 ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/patients', 'clickhouse-01') -- clickhouse-02 ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/patients', 'clickhouse-02')매크로는 같은 SQL로 다른 노드에서 다른 설정을 만들기 위한 템플릿 시스템
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/patients', '{replica}')
매크로 설정 (각 노드별)
clickhouse-01의 cluster.xml
<macros> <cluster>medical_cluster</cluster> <shard>01</shard> <replica>clickhouse-01</replica> </macros>clickhouse-02의 cluster.xml
<macros> <cluster>medical_cluster</cluster> <shard>01</shard> <replica>clickhouse-02</replica> </macros><shard>- 샤드 번호 : 같은 데이터 그룹
<replica>- 레플리카 ID : 노드 고유 식별자
치환 과정 단계별 설명
1단계 : 원본 SQL
CREATE TABLE medical.patients_replica ON CLUSTER medical_cluster ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/patients', '{replica}'){shard}: 매크로 (아직 변수 상태){replica}: 매크로 (아직 변수 상태)
2단계 : ON CLUSTER 명령어의 동작
이 명령어는 클러스터의 모든 노드에서 동시에 실행되지만, 각 노드에서는 자신의 매크로 값으로 치환된다.
clickhouse-01에서 실행될 때
ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/patients', 'clickhouse-01'){shard}⇒ 01 치환- cluster.xml의
<shard>01</shard>
- cluster.xml의
{replica}⇒ clickhouse-01 치환- cluster.xml의
<replica>clickhouse-01</replica>
- cluster.xml의
clickhouse-02에서 실행될 때
ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/patients', 'clickhouse-02'){shard}⇒ 01 치환{replica}⇒ clickhouse-02 치환
매크로 핵심 사항
- 같은 SQL 명령어가 각 노드에서 동일하게 실행
- 단, 개별 매크로 값으로 치환되어 각기 다른 결과 생성
- ZooKeeper 경로는 동일 (
/clickhouse/tables/01/patients) ⇒ 복제 관계 형성 - 레플리카 식별자는 다름 ⇒ 노드 구분
clickhouse-01vsclickhouse-02
ReplicatedMergeTree가 필요한 이유
MergeTree vs ReplicatedMergeTree
일반 MergeTree (단일 노드용)
ENGINE = MergeTree() ORDER BY patient_id- 문제점 : 한 노드에만 데이터 저장
- 위험 : 노드 장애 시 데이터 유실
- 제한 : 확장성 없음
ReplicatedMergeTree (클러스터용)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/patients', '{replica}') ORDER BY patient_id- 장점 : 여러 노드에 동일 데이터 복제
- 안정성 : 노드 장애 시에도 데이터 보존
- 확장성 : 읽기 성능 향상
ReplicatedMergeTree 매개변수
앞서 설명한 매크로를 활용하여 ReplicatedMergeTree를 설정
ReplicatedMergeTree('/clickhouse/tables/{shard}/patients', '{replica}') ↑ ↑ ZooKeeper 경로 레플리카 식별자ZooKeeper 경로 :
/clickhouse/tables/{shard}/patients- 매크로 치환 결과 :
/clickhouse/tables/01/patients - 복제본들이 메타데이터를 공유하는 논리적 경로
- 매크로 치환 결과 :
레플리카 식별자 :
{replica}- 매크로 치환 결과 :
clickhouse-01,clickhouse-02 - 각 노드를 구분하는 고유 ID
- 매크로 치환 결과 :
ZooKeeper 내부 구조
ReplicatedMergeTree가 ZooKeeper에서 복제를 관리하는 방식
/clickhouse/tables/01/patients/ ├── replicas/ │ ├── clickhouse-01/ ← 노드1 정보 │ └── clickhouse-02/ ← 노드2 정보 ├── blocks/ ← 공유 메타데이터 └── mutations/ ← 공유 작업 정보- 이것은 물리적 파일 경로가 아니라 ZooKeeper 내부의 논리적 경로이다
- 같은 테이블의 복제본들이 같은 ZooKeeper 경로를 공유
- 메타데이터와 복제 상태를 함께 관리
데이터 삽입 시 동작 과정
데이터 삽입 시
clickhouse-01에 데이터 삽입
INSERT INTO patients_replica VALUES ('P001', '김철수', ...);ZooKeeper 경로에 메타데이터 기록
/clickhouse/tables/01/patients/blocks/block_12345- 새로운 데이터 블록 정보가 ZooKeeper에 기록된다.
- 두 노드가 모두 이 경로를 감시하고 있다
clickhouse-02가 변경 감지 ⇒ "어?
/clickhouse/tables/01/patients에 새 블록 정보가 생겼네!"⇒ clickhouse-01에서 데이터 복사 시작
복제 완료 후 상태 업데이트
/clickhouse/tables/01/patients/replicas/clickhouse-01/block_12345_synced /clickhouse/tables/01/patients/replicas/clickhouse-02/block_12345_synced
실제 파일 저장 위치 vs ZooKeeper 경로
실제 데이터 파일 저장 위치
실제 파일 : 각 노드의 로컬 디스크에 별도 저장
clickhouse-01
/var/lib/clickhouse/data/medical/patients_replica/ ├── 202401_1_1_0/ ← 2024년 1월 파티션 ├── 202402_2_2_0/ ← 2024년 2월 파티션 └── ...clickhouse-02
/var/lib/clickhouse/data/medical/patients_replica/ ├── 202401_1_1_0/ ← 동일한 데이터 (복제됨) ├── 202402_2_2_0/ ← 동일한 데이터 (복제됨) └── ...
ZooKeeper 메타데이터 경로
/clickhouse/tables/01/patients/ ← 이 경로는 "공유 관리 공간"- 역할 : 두 노드가 복제 상태를 조정하기 위한 공통 관리 공간
복제 테이블 생성과 매크로 활용
클러스터에서는 일반 MergeTree 대신 ReplicatedMergeTree를 사용하여 데이터 복제를 보장한다.
신규 데이터베이스 생성
CREATE DATABASE medical ON CLUSTER medical_cluster;복제 테이블 생성
CREATE TABLE medical.patients_replica ON CLUSTER medical_cluster ( patient_id String, name String, birth_date Date, gender Enum8('M' = 1, 'F' = 2), phone String, registration_date DateTime DEFAULT now(), updated_at DateTime DEFAULT now() ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/patients', '{replica}') ORDER BY patient_id PARTITION BY toYYYYMM(registration_date);- 양쪽 노드에서 자동으로 테이블이 생성되며, ZooKeeper를 통해 복제 관계가 설정된다.
- 핵심 포인트
ON CLUSTER medical_cluster- 클러스터 모든 노드에서 동시 실행
/clickhouse/tables/{shard}/patients- ZooKeeper 경로 (매크로 사용)
{replica}- 각 노드의 고유 식별자
Distributed 테이블이 필요한 이유
ReplicatedMergeTree vs Distributed 역할 구분
- 실제 데이터 저장 (ReplicatedMergeTree) clickhouse-01 : patients_replica (환자 1-50만) clickhouse-02 : patients_replica (환자 1-50만) ← 복제본 - 클라이언트 접근점 (Distributed) patients_distributed → 모든 샤드를 하나의 테이블처럼 통합ReplicatedMergeTree (데이터 저장층)
- 역할 : 실제 데이터를 저장하고 복제 관리
- 특징 : 노드 간 데이터 복제, 장애 복구
- 사용 : 일반적으로는 직접 접근하지 않고 Distributed를 통해 접근
Distributed (클라이언트 접근층)
- 역할 : 여러 샤드의 데이터를 하나의 테이블처럼 통합 제공
- 특징 : 샤딩 로직, 분산 쿼리 처리
- 사용 : 애플리케이션에서 실제로 INSERT/SELECT하는 테이블
왜 Distributed가 필요한가?
Distributed 없이 직접 접근할 때의 문제점
문제점 1 : 어느 노드에 데이터가 있는지 모른다
SELECT * FROM patients_replica WHERE patient_id = 'P12345';- 이 환자가 어느 노드에 있는지 개발자가 직접 찾아야 한다.
문제점 2 : 전체 데이터 조회가 불가능
SELECT COUNT(*) FROM patients_replica;- 한 노드의 데이터만 집계된다, 전체 집계 불가능
문제점 3 : 샤드별로 따로 INSERT 해야 한다
- 개발자가 직접 샤딩 로직을 구현해야 한다
Distributed로 해결
해결 1 : 자동으로 모든 샤드 검색
SELECT * FROM patients_distributed WHERE patient_id = 'P12345';- ClickHouse가 자동으로 모든 노드를 검색해서 결과 반환
해결 2 : 전체 데이터 통합 조회
SELECT COUNT(*) FROM patients_distributed;- 모든 샤드의 데이터를 자동 집계
해결 3 : 자동 샤딩
INSERT INTO patients_distributed VALUES (...);- 샤딩 키에 따라 자동으로 적절한 노드에 분산 저장
분산 테이블 생성과 매개변수
분산 테이블 생성
CREATE TABLE medical.patients_distributed ON CLUSTER medical_cluster ( patient_id String, name String, birth_date Date, gender Enum8('M' = 1, 'F' = 2), phone String, registration_date DateTime DEFAULT now(), updated_at DateTime DEFAULT now() ) ENGINE = Distributed('medical_cluster', 'medical', 'patients_replica', rand());- 앞서 생성한 ReplicatedMergeTree 위에 Distributed 레이어를 구성한다.
Distributed 엔진 매개변수 ⭐
Distributed('medical_cluster', 'medical', 'patients_replica', rand()) ↑ ↑ ↑ ↑ 클러스터 이름 데이터베이스 실제 테이블 샤딩 키- 클러스터 이름
medical_cluster- cluster.xml에서 정의한 이름
- 데이터베이스
medical- 실제 데이터가 있는 데이터베이스
- 실제 테이블
patients_replica- ReplicatedMergeTree 테이블
- 샤딩 키
- 데이터 분산 방식 결정
- 예시)
rand()
- 클러스터 이름
샤딩 키 선택과 데이터 분산 전략
샤딩 키는 데이터가 어느 샤드에 저장될지 결정하는 핵심 요소이다.
랜덤 분산 (
rand())ENGINE = Distributed('medical_cluster', 'medical', 'patients_replica', rand());장점
- 데이터가 모든 샤드에 균등하게 분산
단점
- 특정 데이터 조회 시 모든 샤드를 검색해야 한다
적합한 경우
- 집계 쿼리가 많고, 특정 레코드 조회가 적은 경우
실제 분산 결과
Shard 1: 환자 P001, P005, P007, P012... (랜덤) Shard 2: 환자 P002, P004, P008, P015... (랜덤)
해시 기반 분산 (
cityHash64(키))ENGINE = Distributed('medical_cluster', 'medical', 'patients_replica', cityHash64(patient_id));장점
- 동일한 키는 항상 같은 샤드에 저장
단점
- 데이터 분산이 불균등할 수 있음
적합한 경우
- 특정 환자의 모든 데이터를 자주 조회하는 경우
실제 분산 결과
Shard 1: 환자 P001, P003, P005... (해시값 기준) Shard 2: 환자 P002, P004, P006... (해시값 기준)
날짜 기반 분산 (
toYYYYMM())ENGINE = Distributed('medical_cluster', 'medical', 'patients_replica', toYYYYMM(registration_date));장점
- 특정 기간 조회 시 해당 샤드만 접근
단점
- 최신 데이터가 한 샤드에 집중될 수 있다
적합한 경우
- 시계열 분석이 많은 경우
실제 분산 결과
Shard 1: 2024년 1월 등록 환자들 Shard 2: 2024년 2월 등록 환자들
분산 쿼리 실행 과정
SELECT 쿼리 실행 과정
SELECT gender, COUNT(*) as patient_count, AVG(dateDiff('year', birth_date, now())) as avg_age FROM medical.patients_distributed WHERE registration_date >= '2024-01-01' GROUP BY gender;1단계 : 쿼리 계획 수립
- Query Coordinator (접속한 노드)
- 분산 쿼리 실행 시 최초로 클라이언트가 연결한 ClickHouse 노드
- Query Coordinator가 설정 파일을 보고 "이 쿼리를 모든 샤드에서 실행해야겠다"고 생각
- 쿼리 계획 수립과 하위 쿼리 분배를 담당
- Query Coordinator (접속한 노드)
2단계 : 각 샤드에 하위 쿼리 전송
clickhouse-01에 전송
SELECT gender, COUNT(*) as patient_count, AVG(...) as avg_age FROM medical.patients_replica WHERE registration_date >= '2024-01-01' GROUP BY gender;clickhouse-02에 전송
SELECT gender, COUNT(*) as patient_count, AVG(...) as avg_age FROM medical.patients_replica WHERE registration_date >= '2024-01-01' GROUP BY gender;- 동일한 쿼리
3단계 : 각 샤드에서 부분 결과 반환
clickhouse-01 결과
M 150 32.5 F 200 29.8clickhouse-02 결과
M 180 31.2 F 170 30.1- 동일한 쿼리
4단계 : 결과 병합 및 최종 집계
최종 결과
M 330 31.8 ← (150+180, (32.5*150+31.2*180)/(150+180)) F 370 29.9 ← (200+170, (29.8*200+30.1*170)/(200+170))
INSERT vs SELECT 동작 방식
INSERT 동작 (샤딩 키에 따른 분산)
INSERT INTO medical.patients_distributed VALUES ('P12345', '김철수', '1990-05-15', 'M', '010-1234-5678', now(), now());동작 과정
- 샤딩 키 계산
rand()실행 ⇒ 예 :0.7234
- 샤드 선택
0.7234 * 샤드수(2) = 1.4468⇒ 두 번째 샤드 선택
- 해당 샤드에만 INSERT
- clickhouse-02의 patients_replica에만 저장
- 복제 자동 실행
- ReplicatedMergeTree에 의해 자동 복제
- 샤딩 키 계산
INSERT 결과
clickhouse-01: patients_replica (복제본으로 저장됨) clickhouse-02: patients_replica (원본으로 저장됨)
SELECT 동작 (모든 샤드 조회)
SELECT * FROM medical.patients_distributed WHERE patient_id = 'P12345';- 동작 과정
- 모든 샤드에 쿼리 전송
- 데이터가 어디 있는지 모르기 때문에 모든 샤드에 전송한다.
- 각 샤드에서 검색
clickhouse-01: 결과 없음clickhouse-02: 김철수 데이터 반환
- 결과 병합
- 김철수 데이터만 최종 반환
- 모든 샤드에 쿼리 전송
- 동작 과정
클러스터 환경에서의 쿼리 최적화
WHERE 절 최적화 (파티션 프루닝)
비효율적 : 모든 샤드, 모든 파티션 스캔
SELECT * FROM orders_distributed WHERE customer_name = '김철수';- 이 경우는 샤드 키가
rand()와 같이 샤드 프루닝은 없는 경우이다. - 모든 샤드에 쿼리가 전송되어 불필요한 리소스 소모
- 이 경우는 샤드 키가
효율적 : 특정 파티션만 스캔
SELECT * FROM orders_distributed WHERE order_date >= '2024-01-01' AND order_date < '2024-02-01' AND customer_name = '김철수';- 파티션 프루닝 ⇒ 불필요한 데이터 블록 스킵
- 즉, 불필요한 노드 접근을 차단하여 성능 대폭 향상
GLOBAL JOIN 사용 ⭐
비효율적 : 일반 JOIN
SELECT o.order_id, o.customer_id, c.customer_count FROM orders_distributed o JOIN ( SELECT customer_id, COUNT(*) as customer_count FROM orders_distributed GROUP BY customer_id ) c ON o.customer_id = c.customer_id;- 각 샤드에서 개별적으로 JOIN 수행
- 이 경우 네트워크 트래픽 폭증 및 중복 계산이 발생 될 수 있다.
효율적 : GLOBAL JOIN
SELECT o.order_id, o.customer_id, c.customer_count FROM orders_distributed o GLOBAL JOIN ( SELECT customer_id, COUNT(*) as customer_count FROM orders_distributed GROUP BY customer_id ) c ON o.customer_id = c.customer_id;- 서브쿼리 결과를 한 번만 계산
- 모든 샤드에 브로드캐스트하여 네트워크 효율성 극대화
집계 쿼리 최적화
최적화된 집계 쿼리
SELECT toYYYYMM(order_date) as month, status, COUNT(*) as order_count, uniq(customer_id) as unique_customers, sum(amount) as total_amount FROM orders_distributed WHERE order_date >= '2024-01-01' GROUP BY month, status ORDER BY month DESC SETTINGS distributed_group_by_no_merge = 1, max_distributed_connections = 10, max_threads = 4;- 로컬 집계 최적화
distributed_group_by_no_merge = 1- 각 샤드에서 로컬 집계 후 병합
- 병렬 연결 수 제한
max_distributed_connections = 10- 동시 연결 수 제한
- 스레드 수 제한
max_threads = 4- CPU 리소스 관리
- 로컬 집계 최적화
GROUP BY 최적화
로컬 집계 후 글로벌 병합
-- 대용량 데이터 집계 시 최적화 SELECT product_category, avg(price) as avg_price, count() as product_count FROM products_distributed GROUP BY product_category SETTINGS distributed_group_by_no_merge = 1, group_by_two_level_threshold = 100000;동작 방식
- 각 샤드에서 로컬 GROUP BY 실행
- 중간 결과를 코디네이터 노드로 전송
- 최종 GROUP BY로 결과 병합
장점
- 네트워크 트래픽 대폭 감소
- 메모리 사용량 효율적 관리
- ORDER BY 최적화
LIMIT와 함께 사용하여 중간 결과 크기 제한
-- TOP 100 주문만 조회 SELECT order_id, customer_id, amount, order_date FROM orders_distributed WHERE order_date >= '2024-01-01' ORDER BY amount DESC LIMIT 100 SETTINGS max_bytes_before_external_sort = 1000000000;동작 방식
- 각 샤드에서 TOP 100 선별
- 샤드별 결과를 코디네이터로 전송 (최대 샤드수 × 100개)
- 최종 정렬하여 TOP 100 반환
장점
- 전체 데이터 정렬 없이 효율적 TOP-N 조회
- 메모리 사용량 예측 가능
실무 성능 튜닝
INSERT 최적화
배치 INSERT로 성능 향상
비효율적 : 단건 INSERT
INSERT INTO orders_distributed VALUES ('O001', 'C001', 1000, now()); INSERT INTO orders_distributed VALUES ('O002', 'C002', 2000, now()); INSERT INTO orders_distributed VALUES ('O003', 'C003', 3000, now());효율적 : 배치 INSERT
INSERT INTO orders_distributed VALUES ('O001', 'C001', 1000, now()), ('O002', 'C002', 2000, now()), ('O003', 'C003', 3000, now()), ('O004', 'C004', 4000, now());
비동기 INSERT 설정
비동기 INSERT로 응답 시간 단축
SET insert_distributed_sync = 0; -- 비동기 모드 SET insert_distributed_timeout = 0; -- 타임아웃 무제한 SET async_insert = 1; -- 비동기 배치 처리 SET wait_for_async_insert = 0; -- 완료 대기 안함 INSERT INTO orders_distributed VALUES ('O001', 'C001', 1000, now()), ('O002', 'C002', 2000, now());- 장점 : 클라이언트 응답 시간 대폭 단축
- 주의점 : 데이터 일관성 체크 필요
SELECT 최적화
쿼리 캐시 활용
자주 조회하는 대시보드 쿼리
SELECT toStartOfHour(order_date) as hour, status, COUNT(*) as order_count, sum(amount) as total_amount FROM orders_distributed WHERE order_date >= now() - INTERVAL 24 HOUR GROUP BY hour, status ORDER BY hour DESC SETTINGS use_query_cache = 1, -- 쿼리 캐시 활성화 query_cache_ttl = 300; -- 5분 캐시- 효과 : 동일 쿼리 100-1000배 빠름
- 적용 대상 : 실시간 대시보드, 정기 리포트
메모리 사용량 제한
대용량 데이터 분석 시 메모리 관리
SELECT customer_id, count() as order_count, sum(amount) as total_amount FROM orders_distributed WHERE order_date >= '2023-01-01' GROUP BY customer_id SETTINGS max_memory_usage = 2000000000, -- 2GB 제한 max_bytes_before_external_group_by = 1000000000; -- 1GB 초과시 디스크 사용- 동작 : 메모리 한계 도달 시 자동으로 디스크 사용
- 장점 : 대용량 쿼리도 안정적 실행
복잡한 분석 쿼리
고객 세그먼트별 주문 패턴 분석
SELECT multiIf( total_orders < 5, 'New Customer', total_orders < 20, 'Regular Customer', total_orders < 50, 'VIP Customer', 'Premium Customer' ) as customer_segment, count() as customer_count, avg(avg_order_amount) as segment_avg_amount, sum(total_amount) as segment_total_revenue FROM ( SELECT customer_id, count() as total_orders, avg(amount) as avg_order_amount, sum(amount) as total_amount FROM orders_distributed WHERE order_date >= '2024-01-01' GROUP BY customer_id ) GROUP BY customer_segment ORDER BY segment_total_revenue DESC SETTINGS distributed_group_by_no_merge = 1, max_threads = 8;- 최적화 포인트
- 서브쿼리에서 먼저 고객별 집계
- 외부 쿼리에서 세그먼트별 재집계
- 분산 GROUP BY 최적화 적용
- 최적화 포인트
클러스터 모니터링과 관리
클러스터 상태 확인
분산 테이블 정보 확인
SELECT cluster, shard_num, replica_num, host_name, port, is_local FROM system.clusters WHERE cluster = 'orders_cluster';샤드별 데이터 분포 확인
SELECT hostName() as host, COUNT(*) as record_count, min(order_date) as min_date, max(order_date) as max_date, formatReadableSize(sum(bytes_on_disk)) as data_size FROM orders_replica GROUP BY host ORDER BY record_count DESC;
성능 메트릭 모니터링
쿼리 성능 통계
SELECT query_kind, count() as query_count, avg(query_duration_ms) as avg_duration, max(query_duration_ms) as max_duration, avg(read_rows) as avg_rows_read, avg(memory_usage) as avg_memory FROM system.query_log WHERE event_date = today() AND query LIKE '%orders_distributed%' AND query_duration_ms > 1000 -- 1초 이상 쿼리만 GROUP BY query_kind ORDER BY avg_duration DESC;느린 쿼리 TOP 10
SELECT query, query_duration_ms, memory_usage, read_rows, written_rows, event_time FROM system.query_log WHERE event_date = today() AND type = 'QueryFinish' ORDER BY query_duration_ms DESC LIMIT 10;
데이터 불균형 해결
샤드별 데이터 크기 확인
SELECT hostName() as shard, database, table, formatReadableSize(sum(bytes_on_disk)) as size_on_disk, sum(rows) as total_rows, count() as part_count FROM system.parts WHERE database = 'ecommerce' AND table = 'orders_replica' AND active = 1 GROUP BY hostName(), database, table ORDER BY sum(bytes_on_disk) DESC;파티션별 데이터 분포
SELECT partition, hostName() as shard, sum(rows) as rows_count, formatReadableSize(sum(bytes_on_disk)) as partition_size FROM system.parts WHERE database = 'ecommerce' AND table = 'orders_replica' AND active = 1 GROUP BY partition, hostName() ORDER BY partition, hostName();불균형 해결 방법
- 샤딩 키 변경 (심각한 불균형 시)
- 데이터 재분산 (신중하게)
클러스터 환경에서의 MaterializedView 구성
- ReplicatedSummingMergeTree 활용
-- 실시간 집계 테이블 생성 CREATE TABLE orders.order_stats_realtime ON CLUSTER orders_cluster ( stat_date Date, status Enum8('pending' = 1, 'completed' = 2, 'cancelled' = 3), total_orders UInt32, total_amount UInt64, avg_amount Float32 ) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{shard}/order_stats', '{replica}') ORDER BY (stat_date, status) PARTITION BY toYYYYMM(stat_date);- SummingMergeTree의 핵심 동작
- 동일한
ORDER BY키를 가진 행들의 숫자 컬럼을 자동 합계 - 같은 키의 여러 행을 하나로 병합하여 저장 공간 최적화
- 백그라운드 병합 시 자동으로 합산 실행
- 동일한
- SummingMergeTree의 핵심 동작
- MaterializedView 생성
-- 실시간 집계 MaterializedView CREATE MATERIALIZED VIEW orders.mv_order_stats ON CLUSTER orders_cluster TO orders.order_stats_realtime AS SELECT toDate(order_date) AS stat_date, status, 1 AS total_orders, amount AS total_amount, amount AS avg_amount FROM orders.orders_replica;동작 원리
orders_replica에 새 데이터 INSERT- MaterializedView가 자동으로 트리거
- 변환된 데이터가
order_stats_realtime에 저장 - SummingMergeTree가 자동으로 집계 수행
- 즉, 원본 테이블에 INSERT 시 자동으로 MaterializedView의 SELECT 쿼리가 실행되어 집계 테이블에 데이터 추가한다
증분 업데이트와 데이터 일관성
증분 처리의 핵심
- 새로 들어오는 데이터만 처리하여 성능 최적화
- 기존 집계 결과에 새 값이 집계되어 누적 처리
- 전체 재계산 없이 실시간 업데이트
일관성 보장 메커니즘
- ReplicatedMergeTree로 모든 노드에서 동일한 집계 결과
- ZooKeeper를 통한 메타데이터 동기화
- 노드 장애 시에도 데이터 손실 없이 복구
실시간 대시보드용 집계 구성
분 단위 실시간 통계
-- 1분 단위 실시간 통계 테이블 CREATE TABLE orders.order_stats_minute ON CLUSTER orders_cluster ( minute_window DateTime, operations_count UInt32, revenue UInt64, unique_customers UInt32 ) ENGINE = ReplicatedSummingMergeTree('/clickhouse/tables/{shard}/order_stats_minute', '{replica}') ORDER BY minute_window PARTITION BY toYYYYMMDD(minute_window); -- 실시간 집계 뷰 CREATE MATERIALIZED VIEW orders.mv_order_stats_minute ON CLUSTER orders_cluster TO orders.order_stats_minute AS SELECT toStartOfMinute(order_date) AS minute_window, 1 AS operations_count, amount AS revenue, 1 AS unique_customers FROM orders.orders_replica;실시간 대시보드 쿼리
-- 최근 1시간 실시간 통계 (매우 빠름) SELECT minute_window, sum(operations_count) AS total_orders, sum(revenue) AS total_revenue, sum(unique_customers) AS customer_count FROM orders.order_stats_minute WHERE minute_window >= now() - INTERVAL 1 HOUR GROUP BY minute_window ORDER BY minute_window DESC;- 성능 장점
- 미리 집계된 데이터로 조회 속도 100-1000배 향상
- 대시보드 실시간 업데이트 가능
- 원본 테이블에 부하 없음
- 성능 장점
MaterializedView 활용 패턴
시계열 집계
- 시간별, 일별, 월별 통계 자동 생성
- 트렌드 분석 및 대시보드 최적화
카테고리별 집계
- 상품 카테고리, 지역별, 고객 세그먼트별 통계
- 다차원 분석 데이터 준비
실시간 알림
- 임계값 초과 시 자동 알림
- 이상 패턴 감지 및 모니터링
클러스터 규모 산정
| 일일 데이터량 | 권장 노드 수 | 복제본 수 | 예상 성능 | 최소 메모리 사양 |
|---|---|---|---|---|
| < 1GB | 단일 노드 | 1개 | 실시간 처리 가능 | 8GB |
| 1-10GB | 2-3 노드 | 2개 | 초당 10만 레코드 | 16GB |
| 10-100GB | 4-8 노드 | 2-3개 | 초당 100만 레코드 | 32GB |
| > 100GB | 8+ 노드 | 3개 | 초당 1000만 레코드 | 64GB+ |
노드 수 결정 기준
- 데이터 총량 ÷ 서버당 저장 가능 용량 = 최소 샤드 수
- 동시 쿼리 수 × 평균 응답시간 = 처리 용량 요구사항
- 성장률 고려하여 30-50% 여유 용량 확보
복제본 수 결정 기준
- 일반 서비스
- 2개 (마스터 + 백업)
- 중요 서비스
- 3개 (과반수 쿼럼 확보)
- 읽기 집약적
- 4개 이상 (읽기 부하 분산)
- 일반 서비스
장애 상황별 대응 방안
노드 장애
상황 : 특정 ClickHouse 노드 다운
자동 대응 : 복제본이 자동으로 서비스 계속
수동 조치
-- 복제 상태 확인 SELECT database, table, replica_name, is_leader, absolute_delay FROM system.replicas WHERE database = 'orders'; -- 장애 복구 후 동기화 강제 실행 SYSTEM SYNC REPLICA orders.orders_replica;
ZooKeeper 장애
- 상황 : ZooKeeper 클러스터 다운
- 영향 : 새로운 INSERT 중단, 조회는 계속 가능
- 대응
- ZooKeeper 서비스 재시작
- 연결 복구 확인
- 누락된 데이터 재처리
네트워크 분할
- 상황 : 노드 간 통신 단절
- 자동 대응 : 과반수 노드가 있는 파티션에서만 쓰기 허용
- 수동 조치 : 네트워크 복구 후 데이터 일관성 검증
데이터 불일치
감지
- 샤드별 데이터 개수 비교 SELECT hostName() as host, COUNT(*) as record_count FROM orders.orders_replica GROUP BY host;해결
- 강제 동기화 SYSTEM SYNC REPLICA orders.orders_replica; - 필요시 복제 재시작 SYSTEM RESTART REPLICA orders.orders_replica;
복제 상태 모니터링
복제 지연 확인 (중요!)
SELECT database, table, replica_name, is_leader, absolute_delay, -- 지연 시간 (초) queue_size -- 대기 중인 작업 수 FROM system.replicas WHERE database = 'orders' AND absolute_delay > 60; -- 1분 이상 지연된 경우- 1분 이상 지연된 경우만 확인
분산 DDL 상태 확인
SELECT cluster, query, status, exception FROM system.distributed_ddl_queue WHERE status != 'Finished' ORDER BY initiated_time DESC;
자주 하는 실수들과 해결책
❌ 실수 1 : ZooKeeper 없이 복제 테이블 사용
잘못된 예
ENGINE = ReplicatedMergeTree(...) *- ZooKeeper 설정 없음*해결
- ZooKeeper 설정 필수 확인
설정 파일
<zookeeper>섹션 반드시 포함
❌ 실수 2 : Distributed 테이블에 직접 접근
잘못된 사용
SELECT COUNT(*) FROM orders_replica; - 한 노드 데이터만 조회올바른 사용
SELECT COUNT(*) FROM orders_distributed; - 전체 클러스터 데이터 조회
❌ 실수 3 : GLOBAL JOIN 미사용
비효율적
SELECT ... FROM orders_distributed o JOIN customers_distributed c ON ...; - 네트워크 트래픽 폭증효율적
SELECT ... FROM orders_distributed o GLOBAL JOIN customers_distributed c ON ...; - 한 번만 브로드캐스트
❌ 실수 4 : MaterializedView 오류 무시
- 문제
- 실시간 파이프라인 중단 원인
- 해결
정기적 상태 확인 필수
- MaterializedView 상태 확인 SELECT database, table, engine, create_table_query FROM system.tables WHERE engine = 'MaterializedView';
- 문제
❌ 실수 5 : 파티션 키 없는 WHERE 절
비효율적
SELECT * FROM orders_distributed WHERE customer_id = 'C001';효율적
SELECT * FROM orders_distributed WHERE order_date >= '2024-01-01' AND order_date < '2024-02-01' AND customer_id = 'C001';
프로덕션 환경에서는 절대 SYSTEM 명령어를 함부로 사용하면 안된다. 특히 SYSTEM RESTART REPLICA는 데이터 손실 위험이 있으므로 반드시 백업 후 실행하고, 가능하면 점검 시간에만 수행해야 한다.
상세 설명
모니터링 환경 구성도
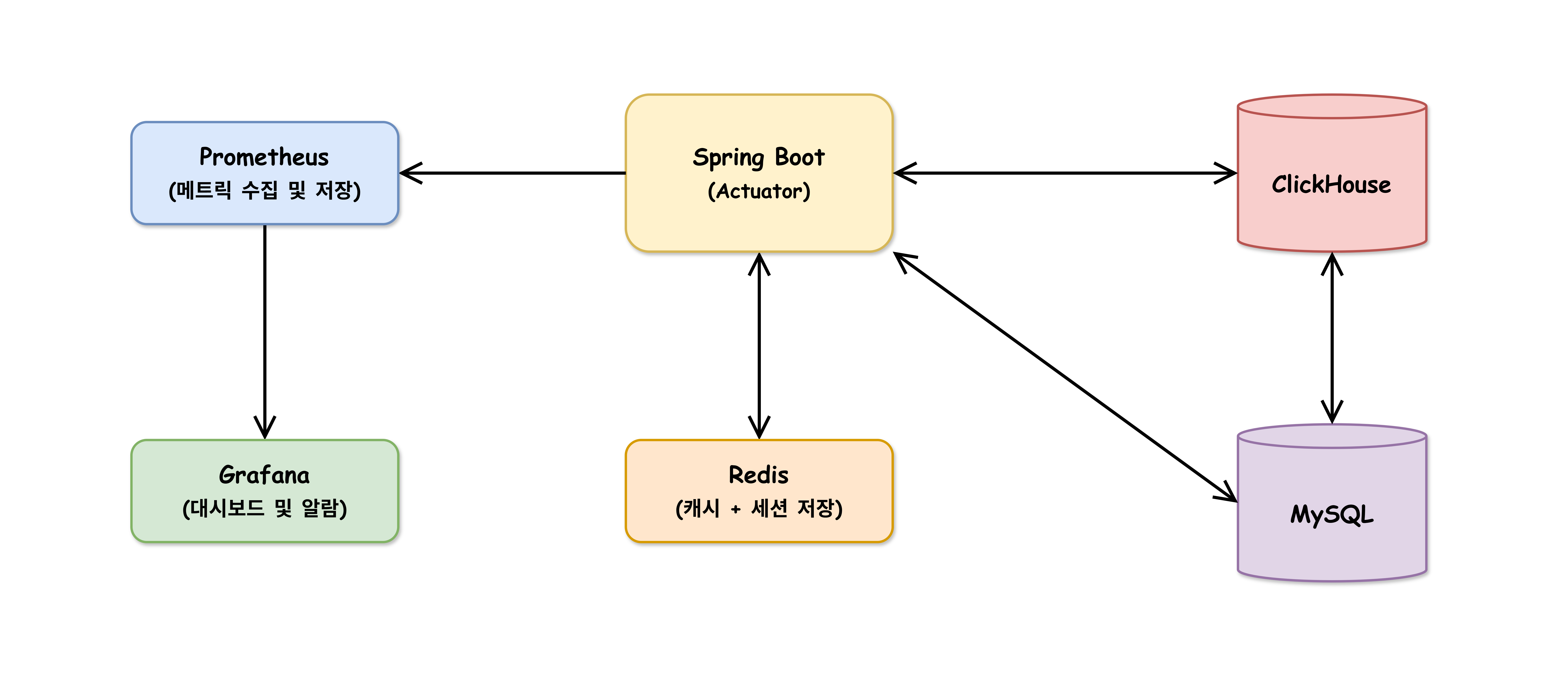
MySQL : OLTP
- 실시간 CRUD 작업
- 정규화된 관계형 데이터
ClickHouse : OLAP
- 대용량 분석 쿼리
- 컬럼형 저장구조
Redis : 인메모리 캐시 + 세션 저장소
- 빠른 응답을 위한 캐싱
- 비로그인 사용자 세션 (장바구니 등)
Prometheus : 시계열 메트릭 수집/저장
- 애플리케이션 성능 지표
- 시스템 리소스 모니터링
Grafana : 시각화 + 알람
- 대시보드로 메트릭 시각화
- 임계치 초과 시 알람 발송
docker-compose.yml
services:
# ClickHouse 데이터베이스
clickhouse:
image: clickhouse/clickhouse-server:latest
container_name: clickhouse-server
hostname: clickhouse-server
ports:
- "8123:8123" # HTTP
- "9000:9000" # Native TCP
volumes:
- clickhouse_data:/var/lib/clickhouse
- clickhouse_logs:/var/log/clickhouse-server
- ./config:/etc/clickhouse-server/config.d:Z
- ./users:/etc/clickhouse-server/users.d:Z
environment:
CLICKHOUSE_USER: ${CLICKHOUSE_USER}
CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD}
CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT: 1
CLICKHOUSE_DB: ${CLICKHOUSE_DB}
ulimits:
nofile: { soft: 262144, hard: 262144 }
healthcheck:
test: ["CMD", "clickhouse", "client", "--query", "SELECT 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
restart: unless-stopped
volumes:
clickhouse_data:
clickhouse_logs:
networks:
default:
name: clickhouse-network
Docker Compose 설정 설명
hostname:
- 컨테이너 내부 네트워크에서 사용할 호스트 이름을 설정
- 다른 컨테이너가 해당 컨테이너에 접속할 때
localhost대신 이hostname을 사용하여 통신할 수 있다. - 이렇게 하면 서로 hostname으로 쉽고 안전하게 통신할 수 있다.
Z 플래그 (
:Z)- 바인드 마운트는 SELinux 환경에서 SELinux 컨텍스트 충돌 가능성이 있기 때문에 Z 플래그를 설정해야 한다.
- 일부 Linux 환경에서 권한 문제 없이 볼륨을 사용하기 위해 필요하다.
- CentOS, RHEL, Fedora 등
- Amazon Linux 2 일부 버전
- Rocky Linux, AlmaLinux 등
- Ubuntu, Debian 기본 설정, macOS, Windows 등의 환경에서 불필요하지만, 범용 버전을 사용하는 것이 좋다.
healthcheck:
healthcheck: test: ["CMD", "clickhouse", "client", "--query", "SELECT 1"] interval: 30s timeout: 10s retries: 3 start_period: 40s- Docker가 컨테이너의 상태를 주기적으로 확인하는 방법
test:- 명령어 조합으로 테스트interval: 30s- 30초마다 한 번씩 검사timeout: 10s- 응답을 10초까지 기다림retries: 3- 3번 연속 실패 시 "unhealthy" 상태 판단
start_period: 40s- 컨테이너가 시작되고 40초 동안은 실패해도 "unhealthy"로 판단하지 않고 기다려준다.
자동 데이터베이스 생성
environment: CLICKHOUSE_USER: admin CLICKHOUSE_PASSWORD: 1234 CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT: 1 CLICKHOUSE_DB: analytics- 컨테이너가 시작될 때
analytics이라는 데이터베이스를 자동으로 생성한다. - 협업 개발 시 유용하다
- 컨테이너가 시작될 때
restart:
services: clickhouse: restart: unless-stoppedrestart: unless-stopped
- 컨테이너 오류 시 자동 재시작
- 단, 사용자가 직접 중지한 경우엔 재시작 안한다
restart: always
- 시스템 재부팅 시에도 자동으로 컨테이너 시작
- 운영환경에서 주로 사용
- 사용자가 직접 중지해도 시스템 재시작 시 다시 시작된다.
volumes:
volumes: clickhouse_data: clickhouse_logs:- 서비스 설정 안의
volumes와는 다른, 최상위 레벨의 volumes 선언부 - Docker가 직접 관리하는 '이름 있는 볼륨'을 생성하겠다고 선언하는 역할만 수행
- 연결을 위해 각 서비스 내부에서 연결시켜 줘야 한다.
- 콜론(
:) 뒤가 비어있는 것은, 특별한 옵션 없이 기본 설정
- 서비스 설정 안의
networks:
networks: default: name: analytics-network- 모든 서비스가 analytics-network라는 동일한 가상 네트워크에 속하도록 설정
custom.xml로 ClickHouse 서버 설정
<?xml version="1.0"?>
<clickhouse>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
</clickhouse>
네트워크 설정 (Network Settings)
<listen_host>0.0.0.0</listen_host> <!-- 외부 접속 허용 --> <http_port>8123</http_port> <tcp_port>9000</tcp_port>- 외부에서 ClickHouse 서버에 접속하는 방법
<listen_host>- 서버가 어떤 네트워크 주소의 요청을 받을지 결정
0.0.0.0: 모든 네트워크 접속 허용127.0.0.1: 오직 서버 내부(localhost)에서의 접속만 허용
<http_port>와<tcp_port>8123(HTTP)9000(TCP)clickhouse-client같은 공식 클라이언트가 사용하는 고성능 통신 프로토콜- 또는 클러스터 내부 통신 용도
환경변수 활용 및 Git 설정
.gitignore 파일
# .gitignore # Mac system files .DS_Store # IDE files .idea/ .vscode/ # Environment variables .env default-user.xml # Generated data and logs data/ logs/.env(민감정보)data/(용량 큰 DB 파일)logs/(런타임 생성 파일)
.env 파일
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=1234 CLICKHOUSE_DB=analytics.env.example 파일
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=NEED_TO_INPUT CLICKHOUSE_DB=analytics
실행 확인 및 프로젝트 구조
실행 확인
# 실행 docker-compose up -d # 상태 확인 docker-compose ps # 로그 확인 docker-compose logs clickhouse # 접속 테스트 curl http://localhost:8123/ping프로젝트 구조
analytics-env/ ├── docker-compose.yml ├── .gitignore ├── .env ├── .env.example ├── config/ │ └── custom.xml └── users/ └── default-user.xmldefault-user.xml는 자동 생성
Prometheus 설정 파일 (prometheus.yml)
# prometheus/prometheus.yml
# 전역 설정
global:
scrape_interval: 15s
evaluation_interval: 15s
# 알림 규칙 파일 경로
rule_files:
- "rules/*.yml"
# 알림 매니저
#alerting:
# alertmanagers:
# - static_configs:
# - targets:
# - alertmanager:9093
scrape_configs:
# ClickHouse 메트릭
- job_name: 'clickhouse'
static_configs:
- targets: ['clickhouse-server:9363']
metrics_path: '/metrics'
scrape_interval: 30s
scrape_timeout: 10s
# Redis 메트릭
- job_name: 'redis'
static_configs:
- targets: ['redis-exporter:9121']
scrape_interval: 30s
# Spring Boot 메트릭
- job_name: 'spring-boot-app'
static_configs:
- targets: ['host.docker.internal:8090']
metrics_path: '/actuator/prometheus'
scrape_interval: 15s
# Prometheus 메트릭
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
scrape_interval: 15s
global 섹션
global: scrape_interval: 15s # 기본 수집 주기 evaluation_interval: 15s # 알림 규칙 확인 주기전역 설정
scrape_interval
- 모든 타겟에서 메트릭을 가져오는 기본 주기
evaluation_interval
- 알림 규칙을 평가하는 주기
그 외 설정
scrape_timeout- 스크랩 요청 타임아웃 (
scrape_timeout: 10s) - 단,
scrape_interval보다 작아야 한다
- 스크랩 요청 타임아웃 (
external_labelsglobal: external_labels: monitor: 'production-monitor' # 모니터링 환경 식별 region: 'asia-northeast-1' # 지역 정보 cluster: 'main-cluster' # 클러스터 정보 datacenter: 'dc1' # 데이터센터 정보query_log_file- Prometheus 엔진이 실행하는 모든 쿼리를 로그 파일에 기록
query_log_file: /prometheus/query.log
rule_files 섹션
rule_files: - "rules/*.yml"prometheus/rules/폴더의 모든 .yml 파일을 알림 규칙으로 읽는다- 규칙 파일을 생성하여 스크랩 대상 서비스의 다운이나 메모리 사용 경고를 알림 설정할 수 있다
scrape_configs 섹션
scrape_configs: - job_name: '<job_name>' # 필수: 작업 이름 static_configs: # 타겟 설정 - targets: ['<target1>', '<target2>'] scrape_interval: <duration> # 선택 scrape_timeout: <duration> # 선택 metrics_path: <path> # 선택: 메트릭 경로 scheme: <scheme> # 선택: http 또는 httpstargets
- docker-compose.yml에서 설정한 hostname과 ports를 바탕으로 설정
- 예시)
targets: ['clickhouse-server:8123']
scrape_interval / scrape_timeout
- 각각의 job의 scrape_interval 설정은 global 설정을 덮어 쓴다
metrics_path
- target 뒤의 URL 경로
http://clickhouse-server:8123/metrics
- 기본값 : /metrics
- target 뒤의 URL 경로
scheme
http또는https
ClickHouse Job ⭐
- job_name: 'clickhouse' static_configs: - targets: ['clickhouse-server:9363'] metrics_path: '/metrics' scrape_interval: 30s scrape_timeout: 10s- 30초마다
http://clickhouse-server:9363/metrics접속 - 10초 안에 응답 없으면 실패 처리
- 기존의 ClickHouse 포트(8123)는 데이터베이스 처리만 집중한다.
- Prometheus 용으로 임의의 9363 포트를 사용하여 포트 분리한다.
- 보안 분리라는 포트 분리의 장점이 있다.
- custom.xml 파일 수정 필요
- 30초마다
Redis Job
- job_name: 'redis' static_configs: - targets: ['redis-exporter:9121'] scrape_interval: 30s- Redis는 자체적으로 Prometheus 형식의 메트릭을 제공하지 않는다
- Redis Exporter는 Redis의
INFO데이터를 받아서 Prometheus가 이해할 수 있는 형식으로 변환
Spring Boot Job
- job_name: 'spring-boot-app' static_configs: - targets: ['host.docker.internal:8090'] metrics_path: '/actuator/prometheus' scrape_interval: 15s- 일부 서비스만 이렇게 매트릭 수집 간격을 좀 더 작게 할 수 있다
- 단, Spring Actuator가 활성화되어 있어야 한다
- micrometer-prometheus 의존성이 필요하다
- http_server_requests 메트릭을 제공해야 한다
host.docker.internal: Docker 컨테이너에서 호스트 머신으로 접근하는 주소- 호스트에서 실행되는 Spring Boot 애플리케이션에 접근
Prometheus 자체 Job
- job_name: 'prometheus' static_configs: - targets: ['localhost:9090'] scrape_interval: 15s- Prometheus 자체의 성능 모니터링
Prometheus 알림 규칙 파일
Prometheus 현재 폴더 구조
prometheus/ ├── prometheus.yml └── rules/ └── alerts.ymlalerts.yml
groups: - name: essential_alerts rules: # 모든 서비스 다운 감지 - alert: ServiceDown expr: up == 0 for: 5m labels: severity: critical annotations: summary: "Service {{ $labels.job }} is down" description: "{{ $labels.job }} has been down for more than 5 minutes" # Redis 서버 실제 다운 - alert: RedisDown expr: redis_up == 0 for: 5m labels: severity: critical annotations: summary: "Redis server is down" description: "Redis server has been down for more than 5 minutes"규칙 파일 리로드
# 컨테이너 외부 curl -X POST http://localhost:9090/-/reload # 또는 컨테이너 내부 docker exec prometheus-server curl -X POST http://localhost:9090/-/reload # 또는 컨테이너에서 시그널 전송 docker exec prometheus-server kill -HUP 1- Prometheus는 시작할 때만 설정 파일을 읽기 때문에 파일 수정 시 리로드 해야 한다
서비스 상태 확인 URL
# 각 서비스 메트릭 확인 URL http://localhost:9363/metrics # ClickHouse http://localhost:9121/metrics # Redis Exporter http://localhost:8090/actuator/prometheus # Spring Boot http://localhost:9090/metrics # Prometheus http://localhost:9090/targets # 타겟 상태 확인 http://localhost:9090/alerts # 알림 상태 확인- 모든 서비스가 정상 작동하는지 확인할 수 있는 URL
- 문제 발생 시 어떤 서비스에 이상이 있는지 빠르게 파악 가능
docker-compose.yml (bitnami Redis)
services:
# ClickHouse 데이터베이스
clickhouse:
image: clickhouse/clickhouse-server:latest
container_name: clickhouse-server
hostname: clickhouse-server
ports:
- "8123:8123" # HTTP
- "9000:9000" # Native TCP
volumes:
- clickhouse_data:/var/lib/clickhouse
- clickhouse_logs:/var/log/clickhouse-server
- ./config:/etc/clickhouse-server/config.d:Z
- ./users:/etc/clickhouse-server/users.d:Z
environment:
CLICKHOUSE_USER: ${CLICKHOUSE_USER}
CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD}
CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT: 1
CLICKHOUSE_DB: ${CLICKHOUSE_DB}
ulimits:
nofile: { soft: 262144, hard: 262144 }
healthcheck:
test: ["CMD", "clickhouse", "client", "--query", "SELECT 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
restart: unless-stopped
# Redis
redis:
image: bitnami/redis:latest
container_name: redis-server
hostname: redis-server
ports:
- "6379:6379"
environment:
REDIS_PORT_NUMBER: 6379
REDIS_MAXMEMORY: 512mb
REDIS_MAXMEMORY_POLICY: allkeys-lru
REDIS_PASSWORD: ${REDIS_PASSWORD}
REDIS_AOF_ENABLED: "yes"
REDIS_LOGLEVEL: notice
REDIS_DISABLE_COMMANDS: FLUSHDB,FLUSHALL
volumes:
- redis_data:/bitnami/redis/data
healthcheck:
test: ["CMD", "redis-cli", "-h", "localhost", "-p", "6379", "-a", "${REDIS_PASSWORD}", "ping"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
restart: unless-stopped
# Redis Exporter
redis-exporter:
image: oliver006/redis_exporter:latest
container_name: redis-exporter
hostname: redis-exporter
ports:
- "9121:9121"
environment:
REDIS_ADDR: "redis://redis-server:6379"
REDIS_PASSWORD: "${REDIS_PASSWORD}"
depends_on:
redis:
condition: service_healthy
restart: unless-stopped
# Prometheus
prometheus:
image: prom/prometheus:latest
container_name: prometheus-server
hostname: prometheus-server
ports:
- "9090:9090"
volumes:
- ./prometheus:/etc/prometheus:Z
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--storage.tsdb.retention.time=30d'
- '--web.enable-lifecycle'
healthcheck:
test: ["CMD", "wget", "--quiet", "--tries=1", "--spider", "http://localhost:9090/-/healthy"]
interval: 30s
timeout: 10s
retries: 3
restart: unless-stopped
depends_on:
- redis-exporter
- clickhouse
volumes:
clickhouse_data:
clickhouse_logs:
redis_data:
prometheus_data:
networks:
default:
name: clickhouse-network
시작 순서 제어
prometheus: # 3번째 시작 depends_on: - redis-exporter # 2번째 시작 - clickhouse # 1번째 시작- depends_on
- 서비스 시작 순서 제어
prometheus가 시작되기 전에redis-exporter와clickhouse가 먼저 시작되도록 보장
- 의존성 관계 명시
- prometheus ⇒ redis-exporter, clickhouse
- 단, 컨테이너 시작만 기다린다. 서비스 준비 완료는 따로 healthcheck 해야 한다.
- 만약, depends_on이 없다면 모든 컨테이너가 동시에 시작한다
- 시작 순서에 따른 오류 발생 가능
- 서비스 시작 순서 제어
- depends_on
bitnami Redis 설정
redis: image: bitnami/redis:latest container_name: redis-server hostname: redis-server ports: - "6379:6379" environment: REDIS_PORT_NUMBER: 6379 REDIS_MAXMEMORY: 512mb REDIS_MAXMEMORY_POLICY: allkeys-lru REDIS_PASSWORD: ${REDIS_PASSWORD} REDIS_AOF_ENABLED: "yes" REDIS_LOGLEVEL: notice REDIS_DISABLE_COMMANDS: FLUSHDB,FLUSHALL volumes: - redis_data:/bitnami/redis/data healthcheck: test: ["CMD", "redis-cli", "-h", "localhost", "-p", "6379", "-a", "${REDIS_PASSWORD}", "ping"] interval: 10s timeout: 5s retries: 5 start_period: 20s restart: unless-stopped- 비밀번호를 설정했으므로 healthcheck 시 Redis 비밀번호를 사용해야 한다
- redis.conf를 쓰는 공식 Redis와 달리 environment를 사용하여 설정한다
- bind는 자동으로 0.0.0.0 설정된다.
- 영속성은 RDB 방식보다 더 안전한 AOF를 사용
- logfile은 자동으로 stdout 처리
- 그 외 여러 설정들은 bitnami가 자동 최적화한다.
Redis Exporter 설정
redis-exporter: image: oliver006/redis_exporter:latest container_name: redis-exporter hostname: redis-exporter ports: - "9121:9121" environment: REDIS_ADDR: "redis://redis-server:6379" REDIS_PASSWORD: "${REDIS_PASSWORD}" depends_on: redis: condition: service_healthy restart: unless-stoppedenvironment:REDIS_ADDR:- Redis Exporter가 어떤 Redis에 연결할지 지정
depends_on:redis:condition:- 헬스체크 통과 후에만 시작
- Prometheus 처럼 컨테이너만 시작되는지 확인하는 것이 아니라, Redis가 완전히 준비될 때까지 기다린다
Prometheus 설정
prometheus: image: prom/prometheus:latest container_name: prometheus-server hostname: prometheus-server ports: - "9090:9090" volumes: - ./prometheus:/etc/prometheus:Z - prometheus_data:/prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' - '--web.console.libraries=/etc/prometheus/console_libraries' - '--web.console.templates=/etc/prometheus/consoles' - '--storage.tsdb.retention.time=30d' - '--web.enable-lifecycle' healthcheck: test: ["CMD", "wget", "--quiet", "--tries=1", "--spider", "http://localhost:9090/-/healthy"] interval: 30s timeout: 10s retries: 3 restart: unless-stopped depends_on: - redis-exporter - clickhouse- command 설정
--web.enable-lifecyclecurl -X POST /-/reload가능하게 하는 것
--storage.tsdb.retention.time=30d- 30일간 메트릭 데이터 보관
- command 설정
ClickHouse Prometheus 설정 추가
ClickHouse에 Prometheus 메트릭 설정이 없으면 메트릭 수집이 되지 않는다
custom.xml
<?xml version="1.0"?> <clickhouse> <listen_host>0.0.0.0</listen_host> <http_port>8123</http_port> <tcp_port>9000</tcp_port> <prometheus> <endpoint>/metrics</endpoint> <!-- 메트릭 URL 경로 --> <port>9363</port> <!-- Prometheus 전용 포트 --> <metrics>true</metrics> <!-- 기본 메트릭 활성화 --> <events>true</events> <!-- 이벤트 메트릭 활성화 --> <asynchronous_metrics>true</asynchronous_metrics> <!-- 비동기 메트릭 활성화 --> <status_info>true</status_info> <!-- 상태 정보 메트릭 활성화 --> </prometheus> </clickhouse>- prometheus 설정
<endpoint>- 메트릭 URL 경로
<port>- 8123 : ClickHouse HTTP API
- 9363 : Prometheus 메트릭 전용
<metrics>- 기본 메트릭 활성화 여부
- CPU, 메모리, 디스크 등 기본 시스템 메트릭
<events>- 이벤트 메트릭 활성화 여부
- 쿼리 실행, 삽입 등 이벤트 카운터
<asynchronous_metrics>- 비동기 메트릭 활성화 여부
- 백그라운드에서 수집되는 메트릭
<status_info>- 상태 정보 메트릭 활성화 여부
- 서버 버전, 상태 등 정적 정보
- prometheus 설정
환경변수 파일 수정 및 실행 확인
.env 파일
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=1234 CLICKHOUSE_DB=analytics # Redis 설정 REDIS_PASSWORD=1234.env.example
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=NEED_TO_INPUT CLICKHOUSE_DB=analytics # Redis 설정 REDIS_PASSWORD=NEED_TO_INPUT프로젝트 구조
analytics-env/ ├── docker-compose.yml ├── .gitignore ├── .env ├── .env.example ├── prometheus/ │ ├── prometheus.yml # Prometheus 메인 설정 │ └── rules/ │ └── alerts.yml # Prometheus 알림 설정 ├── config/ │ └── custom.xml └── users/ └── default-user.xml실행 확인
# 전체 서비스 시작 docker-compose up -d # 상태 확인 docker-compose ps # 로그 확인 (전체) docker-compose logs # 로그 확인 (각 서비스별) docker-compose logs clickhouse docker-compose logs redis docker-compose logs redis-exporter docker-compose logs prometheus # 설정 리로드 (Prometheus) curl -X POST http://localhost:9090/-/reload접속 테스트
curl http://localhost:8123/ping # ClickHouse redis-cli -h localhost -p 6379 -a 1234 ping # Redis curl -s http://localhost:9121/metrics | grep "redis_up" # Redis Exporter curl http://localhost:9090/api/v1/query?query=up # Prometheus- Prometheus의 /api/v1/query?query=up
Prometheus의 표준 HTTP API (
up메트릭)- Prometheus가 자동으로 생성하는 내장 메트릭
예시
$ curl http://localhost:9090/api/v1/query?query=up { "status": "success", "data": { "resultType": "vector", "result": [ { "metric": { "__name__": "up", "instance": "localhost:9090", "job": "prometheus" }, "value": [1755456430.263, "1"] }, { "metric": { "__name__": "up", "instance": "redis-exporter:9121", "job": "redis" }, "value": [1755456430.263, "1"] }, { "metric": { "__name__": "up", "instance": "host.docker.internal:8090", "job": "spring-boot-app" }, "value": [1755456430.263, "0"] }, { "metric": { "__name__": "up", "instance": "clickhouse-server:8123", "job": "clickhouse" }, "value": [1755456430.263, "0"] } ] } }- ✅ prometheus :
"1" - ✅ redis :
"1" - ❌ spring-boot-app :
"0"(연결 실패 - 앱 없음) - ❌ clickhouse :
"0"(연결 실패 - 메트릭 설정이 없을 때 예시)
- ✅ prometheus :
- Prometheus의 /api/v1/query?query=up
웹 UI 접속
Prometheus : http://localhost:9090
Prometheus : http://localhost:9090/graph
ClickHouse : http://localhost:8123/play
(참고) 공식 Redis 설정 파일 (redis.conf)
# redis/redis.conf
# 네트워크 설정
bind 0.0.0.0
port 6379
timeout 0
tcp-keepalive 300
# 메모리 설정
maxmemory 512mb
maxmemory-policy allkeys-lru
# 영속성 설정
save 900 1
save 300 10
save 60 10000
# 로그 설정
loglevel notice
logfile ""
# 보안 설정
requirepass 1234
# 성능 최적화
tcp-backlog 511
databases 16
# 클라이언트 연결 관리
maxclients 10000
# 슬로우 로그 (성능 모니터링)
slowlog-log-slower-than 10000
slowlog-max-len 128
네트워크 설정
bind 0.0.0.0 # 모든 IP에서 접속 허용 (Docker 환경) port 6379 # Redis 기본 포트 timeout 0 # 클라이언트 연결 타임아웃 tcp-keepalive 300 # TCP 연결 유지 시간 (300초)tcp-keepalive 300- 연결이 끊어졌는지 300초마다 확인
timeout 0- 0 = 무제한
메모리 설정
maxmemory 512mb # 최대 메모리 사용량 제한 maxmemory-policy allkeys-lru # 메모리 부족시 LRU 알고리즘으로 삭제maxmemory-policy allkeys-lru- 설정한 메모리가 가득 찼을 때 자동 삭제
- 비즈니스 로직에 따른 캐시 관리와 다른 정책
- LRU (Least Recently Used)
- 가장 오래 사용되지 않은 키 삭제
- 캐시로 사용할 때 최적의 전략
- 다른 옵션
allkeys-random- 랜덤하게 삭제volatile-lru- TTL 설정된 키 중에서만 LRU 삭제volatile-ttl- TTL이 가장 짧은 키부터 삭제
데이터 영속성
save 900 1 # 900초(15분) 내 1개 이상 쓰기 작업 시 저장 save 300 10 # 300초(5분) 내 10개 이상 쓰기 작업 시 저장 save 60 10000 # 60초(1분) 내 10000개 이상 쓰기 작업 시 저장RDB 스냅샷이란
- Redis는 메모리 기반 데이터베이스이다.
- 빠른 속도가 장점이지만 서버 재시작 시 데이터 손실의 위험이 있다.
- RDB 스냅샷은 메모리의 모든 데이터를 디스크에 저장하는 백업 파일
- 스냅샷 생성 과정
- 조건 충족 감지
- 백그라운드 프로세스(BGSAVE) 시작
- 메모리 데이터를 디스크에 저장 (dump.rdb)
- 임시 파일 생성 ⇒ 원본 파일 교체
- 완료 로그 출력
RDB 스냅샷 조건 (OR 조건)
- 읽기 작업은 카운트되지 않는다
save 900 1- 15분간 최소 1번 쓰기 작업 시 (최소 보장)
save 300 10- 5분간 최소 10번 쓰기 작업 시
save 60 10000- 1분간 최소 10000번 쓰기 작업 시 (대용량 처리 시)
로그 설정
loglevel notice # 로그 레벨 logfile "" # 로그 파일 경로loglevel
debug/verbose/notice/warning
logfile
- 로그 파일 경로
""= stdout- 표준 출력 (콘솔/터미널)
- 파일 출력 없음 (개발 환경)
- 로그 확인 방법
docker-compose logs redis # 실시간 로그 확인 docker-compose logs -f redis # 최근 100줄만 보기 docker-compose logs --tail 100 redis
보안 설정
requirepass 1234 # 패스워드 인증- 패스워드 인증
- 패스워드 설정 후 인증 없이 접속하면 거부된다.
- 패스워드 인증
성능 최적화
tcp-backlog 511 # TCP 연결 대기열 크기 databases 16 # 사용할 데이터베이스 개수tcp-backlog
- TCP Backlog란?
- Backlog = 완료 대기 중인 연결들의 대기열
tcp-backlog 511는 최대 511개까지 대기한다는 의미- 동시 연결 요청이 많은 경우 tcp-backlog가 작으면 일부 연결을 거부한다.
- TCP Backlog란?
databases
- Redis 역시 다른 DBMS 처럼 여러 DB를 가질 수 있다
- 16으로 설정한다면 0 ~ 15번의 데이터베이스를 사용하는 것이다.
추가 운영 설정
maxclients 10000 # 최대 동시 접속 클라이언트 수- maxclients 기본값 : 10000
슬로우 로그 (성능 모니터링)
slowlog-log-slower-than 10000 # 10ms 이상 걸리는 명령어 로깅 slowlog-max-len 128 # 슬로우 로그 최대 저장 개수- 성능 문제 디버깅 용도
- slowlog-log-slower-than 기본값 : 10000 (10 ms)
- slowlog-max-len 기본값 : 128
데이터 소스 자동 구성
apiVersion: 1
datasources:
- name: ClickHouse
uid: 'clickhouse-uid'
type: grafana-clickhouse-datasource
access: proxy
isDefault: false
jsonData:
host: 'clickhouse-server'
port: 8123
protocol: 'http'
defaultDatabase: 'analytics'
username: ${CLICKHOUSE_USER}
secureJsonData:
password: ${CLICKHOUSE_PASSWORD}
- name: Prometheus
uid: 'prometheus-uid'
type: prometheus
access: proxy
url: http://prometheus-server:9090
isDefault: true
editable: true
grafana/provisioning/datasources/datasources.yml
- Grafana 시작 시 자동으로 데이터소스를 등록하는 설정
- DB 직접 연결은 추후 비즈니스 모니터링 용도
ClickHouse 데이터소스
datasources: # ClickHouse 데이터소스 - name: ClickHouse uid: 'clickhouse-uid' type: grafana-clickhouse-datasource access: proxy # Grafana 서버를 통한 프록시 연결 isDefault: false # 기본 데이터소스 아님 jsonData: host: 'clickhouse-server' port: 8123 protocol: 'http' defaultDatabase: 'analytics' username: ${CLICKHOUSE_USER} secureJsonData: password: ${CLICKHOUSE_PASSWORD} # 보안 필드로 패스워드 저장type:
- 데이터를 시각화하는 데 필요한 전용 플러그인을 지정하는 역할
- 공식 문서에서 각 타입에 맞는 플러그인을 알 수 있다.
데이터 소스 type ID Prometheus prometheusMySQL mysqlPostgreSQL postgresElasticsearch elasticsearch
access:
proxy- Grafana 서버가 중간에서 연결 (보안 좋음, 일반적)- 브라우저 → Grafana 서버 → 데이터소스
direct- 브라우저가 직접 연결 (빠름, 개발 환경용)- 브라우저 → 데이터소스 (직접 연결)
jsonData:
- 데이터소스 플러그인별 고유 설정을 정의하는 공간
- 일반적인
url필드 대신, 플러그인이 요구하는 상세한 비보안 연결 정보 설정- 주소, 포트, 프로토콜 등
secureJsonData:
- Grafana가 민감한 정보는 암호화하여 데이터베이스에 저장
isDefault:
- 패널 생성 시 기본으로 선택될 데이터소스 여부
isDefault: true- 새 패널/대시보드 생성 시 자동으로 선택되는 데이터소스
- 가장 자주 사용하는 데이터소스에 설정
isDefault: false- 수동으로 선택해야 함
- 여러 데이터소스 중 보조적인 역할
Prometheus 데이터소스
datasources: # Prometheus 데이터소스 - name: Prometheus uid: 'prometheus-uid' type: prometheus access: proxy # Grafana 서버를 통한 프록시 연결 url: http://prometheus-server:9090 # Prometheus 웹 포트 isDefault: true # 기본 데이터소스로 설정 editable: true # UI에서 편집 가능- editable:
editable: true(기본값)editable: true라면 UI에서 데이터소스 설정 편집 가능- 개발/테스트 환경에서 유용
- 만약,
editable: false라면 운영 환경에서 설정 변경을 방지- 즉, 설정을 코드로만 관리하고 싶을 때 사용
- editable:
기본 대시보드 템플릿 (dashboard.yml)
apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: 'Analytics'
folderUid: 'analytics'
type: file
disableDeletion: false
updateIntervalSeconds: 10
allowUiUpdates: true
options:
path: /etc/grafana/provisioning/dashboards
grafana/provisioning/dashboards/dashboard.yml
- 대시보드 자동 로딩 설정
- Grafana가 시작될 때 어디서, 어떻게 대시보드 설정 파일(JSON)들을 가져와서 자동으로 생성할지 정의하는 역할
providers 설정
providers: - name: 'default' # 프로바이더 이름 orgId: 1 # Grafana 조직 ID (기본값) folder: 'Analytics' # 대시보드가 저장될 폴더명 folderUid: 'analytics' # 폴더 고유 식별자 type: file # 파일 시스템에서 로드 disableDeletion: false # UI에서 삭제 허용 updateIntervalSeconds: 10 # 파일 변경 감지 주기 (초) allowUiUpdates: true # UI에서 대시보드 수정 허용 options: path: /etc/grafana/provisioning/dashboards # JSON 파일들이 위치한 경로name:
- 프로비저닝 설정을 식별하기 위한 고유한 이름
- 로그나 관리 화면에서 여러 프로바이더 중 하나를 구분하는 용도
orgId:
- 대시보드가 속할 Grafana 조직의 ID
orgId:1- Grafana 설치 시 기본으로 생성되는 'Main Org.'의 ID
folder:
- 프로비저닝된 대시보드들이 UI에 표시될 폴더의 이름
'Analytics'라는 이름의 폴더가 생성되고 그 안에 대시보드들이 정리된다
folderUid:
- 폴더 이름이 바뀌어도 유지되는 고유 식별자(UID)
type:
- 어떤 방식으로 대시보드를 가져올지 지정
type:file- 지정된 로컬 파일 경로에서 대시보드 파일(.json)을 스캔한다는 의미
disableDeletion:
- UI에서 사용자가 대시보드를 삭제할 수 있는지 여부
disableDeletion:false- UI에서 삭제 가능
- 단, Grafana 재시작 시 대시보드 재생성
disableDeletion:true- UI에서 삭제 버튼 자체가 비활성화
- updateIntervalSeconds:
- 대시보드 파일(.json)의 변경 사항을 감지하는 주기
updateIntervalSeconds:10- 10초마다 한 번씩
path에 지정된 폴더를 확인
- 10초마다 한 번씩
allowUiUpdates:
- UI에서 사용자가 대시보드를 직접 수정하고 저장할 수 있는지 여부
allowUiUpdates:true- UI에서 대시보드를 자유롭게 수정하고 저장 가능
- 주의
- UI에서 수정한 내용은 Grafana DB에 저장
- 만약 수정 이후 원본 json파일이 변경되면 UI에서 수정한 내용은 원본 파일의 내용으로 덮어써진다
options:
type에 따라 달라지는 추가 설정 항목type: file인 경우- 대시보드 json 파일들이 위치한 경로를 지정
/etc/grafana/provisioning/dashboards- Grafana 컨테이너 내부의 경로
- Grafana 공식 Docker 이미지에서 사용하는 default 경로
- 보통docker-compose.yml에서 호스트 폴더를 이 경로에 볼륨 마운트 해서 사용
시스템 모니터링 패널 구성 (analytics-dashboard.json)
{
"id": null,
"title": "ClickHouse & Redis Analytics Dashboard",
"description": "실시간 시스템 성능 및 비즈니스 메트릭 모니터링",
"tags": [
"clickhouse",
"redis",
"analytics"
],
"timezone": "browser",
"refresh": "5s",
"time": {
"from": "now-1h",
"to": "now"
},
"panels": [
{
"id": 1,
"title": "서비스 상태 (Up/Down)",
"type": "stat",
"gridPos": {
"h": 4,
"w": 6,
"x": 0,
"y": 0
},
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "prometheus-uid"
},
"expr": "up",
"legendFormat": "{{job}}"
}
],
"fieldConfig": {
"defaults": {
"thresholds": {
"steps": [
{
"color": "red",
"value": 0
},
{
"color": "green",
"value": 1
}
]
}
}
}
},
{
"id": 2,
"title": "ClickHouse 쿼리 응답 시간 (95th percentile)",
"type": "timeseries",
"gridPos": {
"h": 8,
"w": 12,
"x": 0,
"y": 4
},
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "prometheus-uid"
},
"expr": "histogram_quantile(0.95, rate(ClickHouseProfileEvents_QueryTimeMicroseconds[5m])) / 1000",
"legendFormat": "95th percentile (ms)"
}
]
},
{
"id": 3,
"title": "ClickHouse 메모리 사용량",
"type": "timeseries",
"gridPos": {
"h": 8,
"w": 12,
"x": 12,
"y": 4
},
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "prometheus-uid"
},
"expr": "ClickHouseAsyncMetrics_MemoryResident / 1024 / 1024 / 1024",
"legendFormat": "Memory Usage (GB)"
}
],
"fieldConfig": {
"defaults": {
"unit": "decbytes"
}
}
},
{
"id": 4,
"title": "Redis 캐시 히트율",
"type": "gauge",
"gridPos": {
"h": 8,
"w": 6,
"x": 0,
"y": 12
},
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "prometheus-uid"
},
"expr": "redis_keyspace_hits_total / (redis_keyspace_hits_total + redis_keyspace_misses_total) * 100",
"legendFormat": "Hit Rate %"
}
],
"fieldConfig": {
"defaults": {
"min": 0,
"max": 100,
"unit": "percent",
"thresholds": {
"steps": [
{
"color": "red",
"value": 0
},
{
"color": "yellow",
"value": 70
},
{
"color": "green",
"value": 90
}
]
}
}
}
},
{
"id": 5,
"title": "Redis 연결된 클라이언트 수",
"type": "stat",
"gridPos": {
"h": 4,
"w": 6,
"x": 6,
"y": 12
},
"targets": [
{
"datasource": {
"type": "prometheus",
"uid": "prometheus-uid"
},
"expr": "redis_connected_clients",
"legendFormat": "Connected Clients"
}
]
}
]
}
grafana/provisioning/dashboards/analytics-dashboard.json
- 대시보드 자동 로딩 설정
- JSON 파일로 Grafana 대시보드의 모든 설정을 코드로 정의
- 제목, 패널의 위치와 크기, 각 패널이 사용할 쿼리, 시각화 방법까지 모두 포함
대시보드 전역 설정
{ "id": null, "title": "ClickHouse & Redis Analytics Dashboard", "description": "실시간 시스템 성능 및 비즈니스 메트릭 모니터링", "tags": [ "clickhouse", "redis", "analytics" ], "timezone": "browser", "refresh": "5s", "time": { "from": "now-1h", "to": "now" }, "panels": [refresh:
refresh: "5s"- 5초마다 대시보드 전체를 자동으로 새로고침
- 거의 실시간에 가까운 모니터링
time:
time: { "from": "now-1h", "to": "now" }- 대시보드를 처음 열었을 때 기본으로 보여주는 시간 범위 설정
- 최근 1시간으로 설정
패널 상세 설정
"panels": [ { "id": 1, "title": "서비스 상태 (Up/Down)", "type": "stat", "gridPos": { "h": 4, "w": 6, "x": 0, "y": 0 }, "targets": [ { "datasource": { "type": "prometheus", "uid": "prometheus-uid" }, "expr": "up", "legendFormat": "{{job}}" } ], "fieldConfig": { "defaults": { "thresholds": { "steps": [ { "color": "red", "value": 0 }, { "color": "green", "value": 1 } ] } } } },type (패널 타입)
- 패널이 데이터를 어떤 시각화 형태로 보여줄지 결정
- 주요 패널 타입 종류
패널 타입 주요 기능 및 용도 stat 단일 최신 값을 강조하여 현재 상태 표시 (ex. 현재 접속자 수) timeseries 시계열 그래프 (ex. CPU 사용량) gauge 최소/최대 범위 내에서 현재 값의 수준을 게이지 형태 표시 (ex. 캐시 히트율) barchart 여러 항목의 값을 막대그래프로 비교하여 시각화 table 데이터를 원본에 가까운 테이블 형태로 표시 logs 시간순으로 정렬된 로그 데이터를 탐색하는 데 특화
gridPos (그리드 위치 및 크기)
- 대시보드라는 위에서 패널이 차지할 위치와 크기를 정의
"h": 세로 높이 (칸 수)"w": 가로 너비 (칸 수)"x": 가로 위치 (왼쪽에서 0부터 시작)"y": 세로 위치 (위쪽에서 0부터 시작)- 예시 :
{"h": 4, "w": 6, "x": 0, "y": 0}- 가로 6칸, 세로 4칸 크기로, 대시보드의 가장 왼쪽 위(0,0)에 위치
targets (데이터 쿼리)
- 패널에 표시할 데이터를 가져오기 위한 쿼리 정보를 담는 배열
- 하나의 패널에 여러
targets를 설정하여 여러 데이터를 함께 표시할 수 있다 "datasource"- 이 쿼리를 전송할 데이터 소스의 고유 식별자(UID)와 Type으로 명확히 지정
- 예 :
"type": "prometheus", "uid": "prometheus-uid"
"expr"- 데이터 소스에 보낼 실제 쿼리 문자열
- 예 : Prometheus의 PromQL 쿼리
"legendFormat"- 그래프의 범례나 툴팁에 표시될 데이터의 이름 형식 지정
{{job}}과 같이 레이블 값을 동적으로 가져와 사용할 수 있다
fieldConfig (필드 및 시각화 옵션)
- 쿼리를 통해 가져온 데이터를 어떻게 꾸미고 표현할지 상세하게 설정
- 색상, 단위, 임계값 등 시각적 요소를 제어
"defaults"- 모든 필드에 공통으로 적용될 기본값을 설정
"unit"- 데이터의 단위를 지정
- 예 :
percent,decbytes(B, KB, MB...),ms(밀리초)
"thresholds"- 값의 크기에 따라 색상을 다르게 표시하기 위한 임계값
steps배열 안에color와value를 지정하여 구간별로 색 정의
"min","max"- 게이지나 차트의 최소값과 최대값을 강제로 지정할 때 사용
메트릭 선택 목적
Prometheus 데이터 소스
- 시스템 모니터링 요소
- 서비스 상태 : 전체 시스템 헬스체크
- ClickHouse 쿼리 응답 시간 : 성능 병목 지점 파악
- ClickHouse 메모리 사용량 : 리소스 모니터링
- Redis 캐시 히트율 : Redis 효율성 측정
ClickHouse DB 데이터 소스
- 추후 비즈니스 모니터링을 위한 설정
- 가능한 목록 예시
- 어제 가장 많이 본 상품 Top 10
- 지난주에 발생한 특정 에러 로그의 수
- 시간대별 사용자 접속 현황
- 서울 지역 사용자의 평균 구매 금액
docker-compose.yml
services:
# ClickHouse 데이터베이스
clickhouse:
image: clickhouse/clickhouse-server:latest
container_name: clickhouse-server
hostname: clickhouse-server
ports:
- "8123:8123" # HTTP
- "9000:9000" # Native TCP
volumes:
- clickhouse_data:/var/lib/clickhouse
- clickhouse_logs:/var/log/clickhouse-server
- ./config:/etc/clickhouse-server/config.d:Z
- ./users:/etc/clickhouse-server/users.d:Z
environment:
CLICKHOUSE_USER: ${CLICKHOUSE_USER}
CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD}
CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT: 1
CLICKHOUSE_DB: ${CLICKHOUSE_DB}
ulimits:
nofile: { soft: 262144, hard: 262144 }
healthcheck:
test: ["CMD", "clickhouse", "client", "--query", "SELECT 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
restart: unless-stopped
# Redis
redis:
image: bitnami/redis:latest
container_name: redis-server
hostname: redis-server
ports:
- "6379:6379"
environment:
REDIS_PORT_NUMBER: 6379
REDIS_MAXMEMORY: 512mb
REDIS_MAXMEMORY_POLICY: allkeys-lru
REDIS_PASSWORD: ${REDIS_PASSWORD}
REDIS_AOF_ENABLED: "yes"
REDIS_LOGLEVEL: notice
REDIS_DISABLE_COMMANDS: FLUSHDB,FLUSHALL
volumes:
- redis_data:/bitnami/redis/data
healthcheck:
test: ["CMD", "redis-cli", "-h", "localhost", "-p", "6379", "-a", "${REDIS_PASSWORD}", "ping"]
interval: 30s
timeout: 10s
retries: 3
start_period: 20s
restart: unless-stopped
# Redis Exporter
redis-exporter:
image: oliver006/redis_exporter:latest
container_name: redis-exporter
hostname: redis-exporter
ports:
- "9121:9121"
environment:
REDIS_ADDR: "redis://redis-server:6379"
REDIS_PASSWORD: "${REDIS_PASSWORD}"
depends_on:
redis:
condition: service_healthy
restart: unless-stopped
# Prometheus
prometheus:
image: prom/prometheus:latest
container_name: prometheus-server
hostname: prometheus-server
ports:
- "9090:9090"
volumes:
- ./prometheus:/etc/prometheus:Z
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--storage.tsdb.retention.time=30d'
- '--web.enable-lifecycle'
healthcheck:
test: ["CMD", "wget", "--quiet", "--tries=1", "--spider", "http://localhost:9090/-/healthy"]
interval: 30s
timeout: 10s
retries: 3
restart: unless-stopped
depends_on:
- redis-exporter
- clickhouse
# Grafana
grafana:
image: grafana/grafana:latest
container_name: grafana-server
hostname: grafana-server
ports:
- "3000:3000"
environment:
GF_SECURITY_ADMIN_PASSWORD: ${GRAFANA_ADMIN_PASSWORD}
GF_INSTALL_PLUGINS: grafana-clickhouse-datasource
GF_SECURITY_ALLOW_EMBEDDING: true
GF_AUTH_ANONYMOUS_ENABLED: false
GF_PATHS_PROVISIONING: /etc/grafana/provisioning
CLICKHOUSE_USER: ${CLICKHOUSE_USER}
CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD}
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning:/etc/grafana/provisioning:Z
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/api/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 30s
restart: unless-stopped
depends_on:
prometheus:
condition: service_healthy
clickhouse:
condition: service_healthy
volumes:
clickhouse_data:
clickhouse_logs:
redis_data:
prometheus_data:
grafana_data:
networks:
default:
name: clickhouse-network
Grafana 설정
grafana: image: grafana/grafana:latest container_name: grafana-server hostname: grafana-server ports: - "3000:3000" environment: GF_SECURITY_ADMIN_PASSWORD: ${GRAFANA_ADMIN_PASSWORD} # Grafana 관리자 계정 비밀번호 GF_INSTALL_PLUGINS: grafana-clickhouse-datasource # ClickHouse 연동을 위한 플러그인 자동 설치 GF_SECURITY_ALLOW_EMBEDDING: true # 다른 웹페이지에 대시보드 임베딩 허용 GF_AUTH_ANONYMOUS_ENABLED: false # 익명 접속 차단, 로그인 필수 GF_PATHS_PROVISIONING: /etc/grafana/provisioning # 자동 구성 파일 경로 지정 CLICKHOUSE_USER: ${CLICKHOUSE_USER} # 데이터소스 설정에서 사용할 ClickHouse 사용자명 CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD} # 데이터소스 설정에서 사용할 ClickHouse 비밀번호 volumes: - grafana_data:/var/lib/grafana - ./grafana/provisioning:/etc/grafana/provisioning:Z healthcheck: test: ["CMD", "curl", "-f", "http://localhost:3000/api/health"] interval: 30s timeout: 10s retries: 3 start_period: 30s restart: unless-stopped depends_on: prometheus: condition: service_healthy clickhouse: condition: service_healthyGF_INSTALL_PLUGINS
- Grafana 시작 시 자동으로 설치할 플러그인 목록 지정
grafana-clickhouse-datasource- ClickHouse 데이터베이스와 연동하는 전용 플러그인
- 수동 플러그인 설치 과정 생략, 컨테이너 재시작 시에도 자동 설치
- 없으면 ClickHouse를 데이터소스로 추가할 수 없어 대시보드 구성 불가
GF_SECURITY_ALLOW_EMBEDDING
- 다른 웹사이트나 앱에서 iframe으로 Grafana 대시보드 임베딩 허용 여부
GF_SECURITY_ALLOW_EMBEDDING: true- 사내 포털이나 다른 관리 도구에 대시보드 통합 가능
- 보안 고려 : 신뢰할 수 있는 도메인에서만 사용하도록 주의 필요
GF_SECURITY_ALLOW_EMBEDDING: false- 임베딩 차단, Grafana 사이트에서만 접근 가능
GF_AUTH_ANONYMOUS_ENABLED
- Grafana 시작 시 자동으로 설치할 플러그인 목록 지정
GF_AUTH_ANONYMOUS_ENABLED: false- 모든 사용자가 로그인해야 Grafana 접근 가능 (권장)
- 사용자 추적 가능, 권한 관리, 보안성 향상
GF_AUTH_ANONYMOUS_ENABLED: true- 로그인 없이 익명으로 대시보드 조회 가능
GF_PATHS_PROVISIONING
- Grafana가 자동 구성 파일들을 찾을 경로 지정
/etc/grafana/provisioning- Grafana 공식 Docker 이미지의 기본 프로비저닝 경로
- 없으면 datasources.yml, dashboard.yml 등 자동 구성 파일을 인식하지 못한다
- 수동으로 데이터소스와 대시보드를 GUI에서 설정해야 한다
CLICKHOUSE_USER
- datasources.yml에서 환경변수로 참조하기 위해 전달
CLICKHOUSE_PASSWORD
- datasources.yml의 secureJsonData에서 환경변수로 참조하기 위해 전달
환경변수 파일 수정 및 실행 확인
.env 파일
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=1234 CLICKHOUSE_DB=analytics # Redis 설정 REDIS_PASSWORD=1234 # Grafana 설정 GRAFANA_ADMIN_PASSWORD=admin1234.env.example
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=NEED_TO_INPUT CLICKHOUSE_DB=analytics # Redis 설정 REDIS_PASSWORD=NEED_TO_INPUT # Grafana 설정 GRAFANA_ADMIN_PASSWORD=NEED_TO_INPUT프로젝트 구조
analytics-env/ ├── docker-compose.yml ├── .gitignore ├── .env ├── .env.example ├── grafana/ # Grafana 대시보드 설정 │ └── provisioning/ │ ├── datasources/ │ │ └── datasources.yml # 데이터소스 자동 구성 │ └── dashboards/ │ ├── analytics-dashboard.json # 시스템 모니터링 패널 구성 │ └── dashboard.yml # 기본 대시보드 템플릿 ├── prometheus/ │ ├── prometheus.yml │ └── rules/ │ └── alerts.yml ├── config/ │ └── custom.xml └── users/ └── default-user.xml실행 확인
# 전체 서비스 시작 docker-compose up -d # 상태 확인 docker-compose ps # 로그 확인 (전체) docker-compose logs # Grafana 로그 확인 docker-compose logs grafana접속 테스트
# Grafana 헬스체크 curl -f http://localhost:3000/api/health웹 UI 접속
Grafana : http://localhost:3000
- ID :
admin - PW :
admin1234
- ID :
- Connections의 Data sources 확인
- Prometheus, ClickHouse
- Dashboards 확인
- ClickHouse & Redis Analytics Dashboard
MySQL 추가
ClickHouse 설정 폴더 구조 변경
docker-compose.yml 수정
services: # ClickHouse 데이터베이스 clickhouse: image: clickhouse/clickhouse-server:latest container_name: clickhouse-server hostname: clickhouse-server ports: - "8123:8123" # HTTP - "9000:9000" # Native TCP volumes: - clickhouse_data:/var/lib/clickhouse - clickhouse_logs:/var/log/clickhouse-server - ./clickhouse/config:/etc/clickhouse-server/config.d:Z - ./clickhouse/users:/etc/clickhouse-server/users.d:Z environment: ...변경 사항
./config⇒./clickhouse/config./users⇒./clickhouse/users
프로젝트 구조 변경
analytics-env/ ├── docker-compose.yml ├── .gitignore ├── .env ├── .env.example ├── grafana/ │ └── provisioning/ │ ├── datasources/ │ │ └── datasources.yml │ └── dashboards/ │ ├── analytics-dashboard.json │ └── dashboard.yml ├── prometheus/ │ ├── prometheus.yml │ └── rules/ │ └── alerts.yml └── clickhouse/ ├── config/ │ └── custom.xml └── users/ └── default-user.xml
docker-compose.yml 수정 (MySQL 추가)
services: # MySQL mysql: image: mysql:8.0 container_name: mysql-server hostname: mysql-server ports: - "3306:3306" environment: MYSQL_ROOT_PASSWORD: ${MYSQL_ROOT_PASSWORD} MYSQL_DATABASE: ${MYSQL_DATABASE} MYSQL_USER: ${MYSQL_USER} MYSQL_PASSWORD: ${MYSQL_PASSWORD} MYSQL_EXPORTER_USER: ${MYSQL_EXPORTER_USER} MYSQL_EXPORTER_PASSWORD: ${MYSQL_EXPORTER_PASSWORD} volumes: - mysql_data:/var/lib/mysql - ./mysql/init:/docker-entrypoint-initdb.d:Z restart: unless-stopped healthcheck: test: ["CMD", "mysqladmin", "ping", "-h", "localhost", "-u", "root", "-p${MYSQL_ROOT_PASSWORD}"] interval: 30s timeout: 10s retries: 3 start_period: 40s # MySQL Exporter mysql-exporter: image: prom/mysqld-exporter container_name: mysql-exporter hostname: mysql-exporter ports: - "9104:9104" environment: MYSQLD_EXPORTER_PASSWORD: ${MYSQL_EXPORTER_PASSWORD} command: - '--mysqld.address=mysql-server:3306' - '--mysqld.username=exporter' depends_on: - mysql restart: unless-stopped # ClickHouse clickhouse: ... # Grafana grafana: image: grafana/grafana:latest container_name: grafana-server hostname: grafana-server ports: - "3000:3000" environment: GF_SECURITY_ADMIN_PASSWORD: ${GRAFANA_ADMIN_PASSWORD} GF_INSTALL_PLUGINS: grafana-clickhouse-datasource GF_SECURITY_ALLOW_EMBEDDING: true GF_AUTH_ANONYMOUS_ENABLED: false GF_PATHS_PROVISIONING: /etc/grafana/provisioning CLICKHOUSE_USER: ${CLICKHOUSE_USER} CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD} MYSQL_EXPORTER_USER: ${MYSQL_EXPORTER_USER} MYSQL_EXPORTER_PASSWORD: ${MYSQL_EXPORTER_PASSWORD} MYSQL_DATABASE: ${MYSQL_DATABASE} volumes: - grafana_data:/var/lib/grafana - ./grafana/provisioning:/etc/grafana/provisioning:Z healthcheck: test: ["CMD", "curl", "-f", "http://localhost:3000/api/health"] interval: 30s timeout: 10s retries: 3 start_period: 30s restart: unless-stopped depends_on: prometheus: condition: service_healthy clickhouse: condition: service_healthy volumes: mysql_data: clickhouse_data: clickhouse_logs: redis_data: prometheus_data: grafana_data:Exporter 사용자 생성 및 권한 부여 스크립트 파일 생성
#!/bin/bash set -e mysql -u root -p"$MYSQL_ROOT_PASSWORD" <<-EOSQL CREATE USER IF NOT EXISTS '$MYSQL_EXPORTER_USER'@'%' IDENTIFIED WITH mysql_native_password BY '$MYSQL_EXPORTER_PASSWORD'; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO '$MYSQL_EXPORTER_USER'@'%'; FLUSH PRIVILEGES; EOSQL./mysql/init 폴더를 생성하고 init.sh 파일 생성
- init.sql 파일도 가능하지만, 환경 변수를 사용하기 편한 방법을 선택
- 단, 환경 변수는 docker-compose.yml을 통해 .env의 변수를 가져와서 사용 가능
이 파일의 목적은
mysql-exporter가 MySQL 서버의 전반적인 상태를 읽어올 수 있도록 권한 부여- 권한이 없는 경우,
mysql-exporter가 Restarting 상태로 무한 재시작 발생
- 권한이 없는 경우,
- 스크립트 파일 실행
/docker-entrypoint-initdb.d/는 공식 이미지의 공식 엔트리포인트 경로- 공식 MySQL 엔트리포인트가 공식 경로를 스캔하여 스크립트 파일 자동 실행
만일 명확한 제어가 필요한 경우
mysql: ... volumes: - mysql_data:/var/lib/mysql - ./mysql/init:/docker-entrypoint-initdb.d:Z command: > bash -c " chmod +x /docker-entrypoint-initdb.d/init.sh && docker-entrypoint.sh mysqld "
결과 확인
$ docker exec -it mysql-server mysql -uroot -p1234 mysql> SELECT User, Host FROM mysql.user WHERE User='exporter'; +----------+------+ | User | Host | +----------+------+ | exporter | % | +----------+------+ 1 row in set (0.01 sec)
.env / .env.example 수정
.env 파일
# MySQL 설정 MYSQL_ROOT_PASSWORD=1234 MYSQL_DATABASE=analytics MYSQL_USER=admin MYSQL_PASSWORD=admin1234 # MySQL Exporter 설정 MYSQL_EXPORTER_USER=exporter MYSQL_EXPORTER_PASSWORD=exporter1234.env.example 파일
# MySQL 설정 MYSQL_ROOT_PASSWORD=NEED_TO_INPUT MYSQL_DATABASE=analytics MYSQL_USER=admin MYSQL_PASSWORD=NEED_TO_INPUT # MySQL Exporter 설정 MYSQL_EXPORTER_USER=exporter MYSQL_EXPORTER_PASSWORD=NEED_TO_INPUT
Prometheus의 prometheus.yml 수정
global: ... scrape_configs: # ClickHouse 메트릭 - job_name: 'clickhouse' ... # MySQL 메트릭 - job_name: 'mysql' static_configs: - targets: ['mysql-exporter:9104']- Prometheus의 default
metrics_path값은/metrics - mysql-exporter와 redis-exporter는 모두 이 표준 경로를 사용하므로
metrics_path생략 가능 scrape_interval등은 전역 설정 사용하므로 생략
- Prometheus의 default
Grafana의 datasources.yml 수정
apiVersion: 1 datasources: - name: ClickHouse ... - name: MySQL uid: 'mysql-uid' type: mysql access: proxy isDefault: false url: mysql-server:3306 database: ${MYSQL_DATABASE} user: ${MYSQL_EXPORTER_USER} secureJsonData: password: ${MYSQL_EXPORTER_PASSWORD} - name: Prometheus ...- 환경 변수를 바로 읽어올 수 있는 것이 아니기 때문에 docker-compose.yml에서 grafana에 설정한 환경 변수를 통해 가져온다.
Grafana의 analytics-dashboard.json 수정
... }, { "id": 6, "title": "MySQL 활성 연결 수", "type": "stat", "gridPos": { "h": 4, "w": 6, "x": 0, "y": 20 }, "targets": [ { "datasource": { "type": "prometheus", "uid": "prometheus-uid" }, "expr": "mysql_global_status_threads_connected", "legendFormat": "Active Connections" } ] }, { "id": 7, "title": "MySQL 초당 쿼리 수 (QPS)", "type": "timeseries", "gridPos": { "h": 8, "w": 18, "x": 6, "y": 20 }, "targets": [ { "datasource": { "type": "prometheus", "uid": "prometheus-uid" }, "expr": "rate(mysql_global_status_queries[5m])", "legendFormat": "Queries Per Second" } ], "fieldConfig": { "defaults": { "unit": "qps" } } } ] }- MySQL 활성 연결 수 ⇒ 서버 부하 측정
- MySQL 초당 쿼리 수 ⇒ QPS - 서버 성능 측정
환경별 Docker Compose 파일
docker-compose.yml (최종)
services: mysql: image: mysql:8.0 container_name: mysql-server hostname: mysql-server ports: - "3306:3306" environment: MYSQL_ROOT_PASSWORD: ${MYSQL_ROOT_PASSWORD} MYSQL_DATABASE: ${MYSQL_DATABASE} MYSQL_USER: ${MYSQL_USER} MYSQL_PASSWORD: ${MYSQL_PASSWORD} MYSQL_EXPORTER_USER: ${MYSQL_EXPORTER_USER} MYSQL_EXPORTER_PASSWORD: ${MYSQL_EXPORTER_PASSWORD} volumes: - mysql_data:/var/lib/mysql - ./mysql/init:/docker-entrypoint-initdb.d:Z restart: unless-stopped healthcheck: test: ["CMD", "mysqladmin", "ping", "-h", "localhost", "-u", "root", "-p${MYSQL_ROOT_PASSWORD}"] interval: 30s timeout: 10s retries: 3 start_period: 40s mysql-exporter: image: prom/mysqld-exporter container_name: mysql-exporter hostname: mysql-exporter ports: - "9104:9104" environment: MYSQLD_EXPORTER_PASSWORD: ${MYSQL_EXPORTER_PASSWORD} command: - '--mysqld.address=mysql-server:3306' - '--mysqld.username=exporter' depends_on: mysql: condition: service_healthy restart: unless-stopped clickhouse: image: clickhouse/clickhouse-server:latest container_name: clickhouse-server hostname: clickhouse-server ports: - "8123:8123" # HTTP - "9000:9000" # Native TCP volumes: - clickhouse_data:/var/lib/clickhouse - clickhouse_logs:/var/log/clickhouse-server - ./clickhouse/config:/etc/clickhouse-server/config.d:Z - ./clickhouse/users:/etc/clickhouse-server/users.d:Z environment: CLICKHOUSE_USER: ${CLICKHOUSE_USER} CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD} CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT: 1 CLICKHOUSE_DB: ${CLICKHOUSE_DB} ulimits: nofile: { soft: 262144, hard: 262144 } healthcheck: test: ["CMD", "clickhouse", "client", "--query", "SELECT 1"] interval: 30s timeout: 10s retries: 3 start_period: 40s restart: unless-stopped redis: image: bitnami/redis:latest container_name: redis-server hostname: redis-server ports: - "6379:6379" environment: REDIS_PORT_NUMBER: 6379 REDIS_MAXMEMORY: 512mb REDIS_MAXMEMORY_POLICY: allkeys-lru REDIS_PASSWORD: ${REDIS_PASSWORD} REDIS_AOF_ENABLED: "yes" REDIS_LOGLEVEL: notice REDIS_DISABLE_COMMANDS: FLUSHDB,FLUSHALL volumes: - redis_data:/bitnami/redis/data healthcheck: test: ["CMD", "redis-cli", "-h", "localhost", "-p", "6379", "-a", "${REDIS_PASSWORD}", "ping"] interval: 30s timeout: 10s retries: 3 start_period: 20s restart: unless-stopped redis-exporter: image: oliver006/redis_exporter:latest container_name: redis-exporter hostname: redis-exporter ports: - "9121:9121" environment: REDIS_ADDR: "redis://redis-server:6379" REDIS_PASSWORD: "${REDIS_PASSWORD}" depends_on: redis: condition: service_healthy restart: unless-stopped prometheus: image: prom/prometheus:latest container_name: prometheus-server hostname: prometheus-server ports: - "9090:9090" volumes: - ./prometheus:/etc/prometheus:Z - prometheus_data:/prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' - '--web.console.libraries=/etc/prometheus/console_libraries' - '--web.console.templates=/etc/prometheus/consoles' - '--storage.tsdb.retention.time=30d' - '--web.enable-lifecycle' healthcheck: test: ["CMD", "wget", "--quiet", "--tries=1", "--spider", "http://localhost:9090/-/healthy"] interval: 30s timeout: 10s retries: 3 restart: unless-stopped grafana: image: grafana/grafana:latest container_name: grafana-server hostname: grafana-server ports: - "3000:3000" environment: GF_SECURITY_ADMIN_PASSWORD: ${GRAFANA_ADMIN_PASSWORD} GF_INSTALL_PLUGINS: grafana-clickhouse-datasource GF_SECURITY_ALLOW_EMBEDDING: true GF_AUTH_ANONYMOUS_ENABLED: false GF_PATHS_PROVISIONING: /etc/grafana/provisioning CLICKHOUSE_USER: ${CLICKHOUSE_USER} CLICKHOUSE_PASSWORD: ${CLICKHOUSE_PASSWORD} MYSQL_EXPORTER_USER: ${MYSQL_EXPORTER_USER} MYSQL_EXPORTER_PASSWORD: ${MYSQL_EXPORTER_PASSWORD} MYSQL_DATABASE: ${MYSQL_DATABASE} volumes: - grafana_data:/var/lib/grafana - ./grafana/provisioning:/etc/grafana/provisioning:Z healthcheck: test: ["CMD", "curl", "-f", "http://localhost:3000/api/health"] interval: 30s timeout: 10s retries: 3 start_period: 30s restart: unless-stopped depends_on: prometheus: condition: service_healthy clickhouse: condition: service_healthy mysql: condition: service_healthy volumes: mysql_data: clickhouse_data: clickhouse_logs: redis_data: prometheus_data: grafana_data: networks: default: name: clickhouse-networkdocker-compose.prod.yml
services: mysql: restart: always mysql-exporter: restart: always clickhouse: restart: always redis: restart: always redis-exporter: restart: always prometheus: restart: always grafana: restart: always- 기본 설정은 그대로 사용
- restart 정책만
unless-stopped에서always로 변경- 개발 환경의 편의성을 위해
unless-stopped를 사용
- 개발 환경의 편의성을 위해
운영 환경 파일 설정
.env 파일
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=1234 CLICKHOUSE_DB=analytics # Redis 설정 REDIS_PASSWORD=1234 # Grafana 설정 GRAFANA_ADMIN_PASSWORD=admin1234 # MySQL 설정 MYSQL_ROOT_PASSWORD=1234 MYSQL_DATABASE=analytics MYSQL_USER=admin MYSQL_PASSWORD=admin1234 # MySQL Exporter 설정 MYSQL_EXPORTER_USER=exporter MYSQL_EXPORTER_PASSWORD=exporter1234- 개발 환경
.env.prod 파일
CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=1234 CLICKHOUSE_DB=analytics_prod REDIS_PASSWORD=1234 GRAFANA_ADMIN_PASSWORD=admin1234 MYSQL_ROOT_PASSWORD=1234 MYSQL_DATABASE=analytics_prod MYSQL_USER=admin MYSQL_PASSWORD=admin1234 MYSQL_EXPORTER_USER=exporter MYSQL_EXPORTER_PASSWORD=exporter1234- 운영 환경에 맞게 비밀번호 등을 알아서 수정하고 사용하면 된다
.env.example
# ClickHouse 설정 CLICKHOUSE_USER=admin CLICKHOUSE_PASSWORD=NEED_TO_INPUT CLICKHOUSE_DB=analytics # Redis 설정 REDIS_PASSWORD=NEED_TO_INPUT # Grafana 설정 GRAFANA_ADMIN_PASSWORD=NEED_TO_INPUT # MySQL 설정 MYSQL_ROOT_PASSWORD=NEED_TO_INPUT MYSQL_DATABASE=analytics MYSQL_USER=admin MYSQL_PASSWORD=NEED_TO_INPUT # MySQL Exporter 설정 MYSQL_EXPORTER_USER=exporter MYSQL_EXPORTER_PASSWORD=NEED_TO_INPUT
프로젝트 디렉토리 구조
analytics-env/ ├── docker-compose.yml ├── docker-compose.prod.yml # 운영환경 설정 ├── .gitignore ├── .env ├── .env.prod # 운영환경 설정 ├── .env.example ├── mysql/ │ └── init/ │ └── init.sh ├── grafana/ │ └── provisioning/ │ ├── datasources/ │ │ └── datasources.yml │ └── dashboards/ │ ├── analytics-dashboard.json │ └── dashboard.yml ├── prometheus/ │ ├── prometheus.yml │ └── rules/ │ └── alerts.yml └── clickhouse/ ├── config/ │ └── custom.xml └── users/ └── default-user.xml환경별 실행 방법
실행 명령어
- 개발 환경
docker-compose up -d - 운영 환경
docker-compose --env-file .env.prod -f docker-compose.yml -f docker-compose.prod.yml up -d - 운영 환경의 경우
docker-compose.yml은 기본 설정 + 운영환경 오버라이드- 환경 설정 파일은
.env.prod사용
- 개발 환경
정지 명령어
- 개발 환경
docker-compose down - 운영 환경
docker-compose --env-file .env.prod -f docker-compose.yml -f docker-compose.prod.yml down - 컨테이너 데이터 삭제 + 정지
docker-compose down -v- 주의 : 컨테이너가 관리하는 데이터가 다 초기화됨
- 개발 환경
실행 확인
Grafana Dashboard
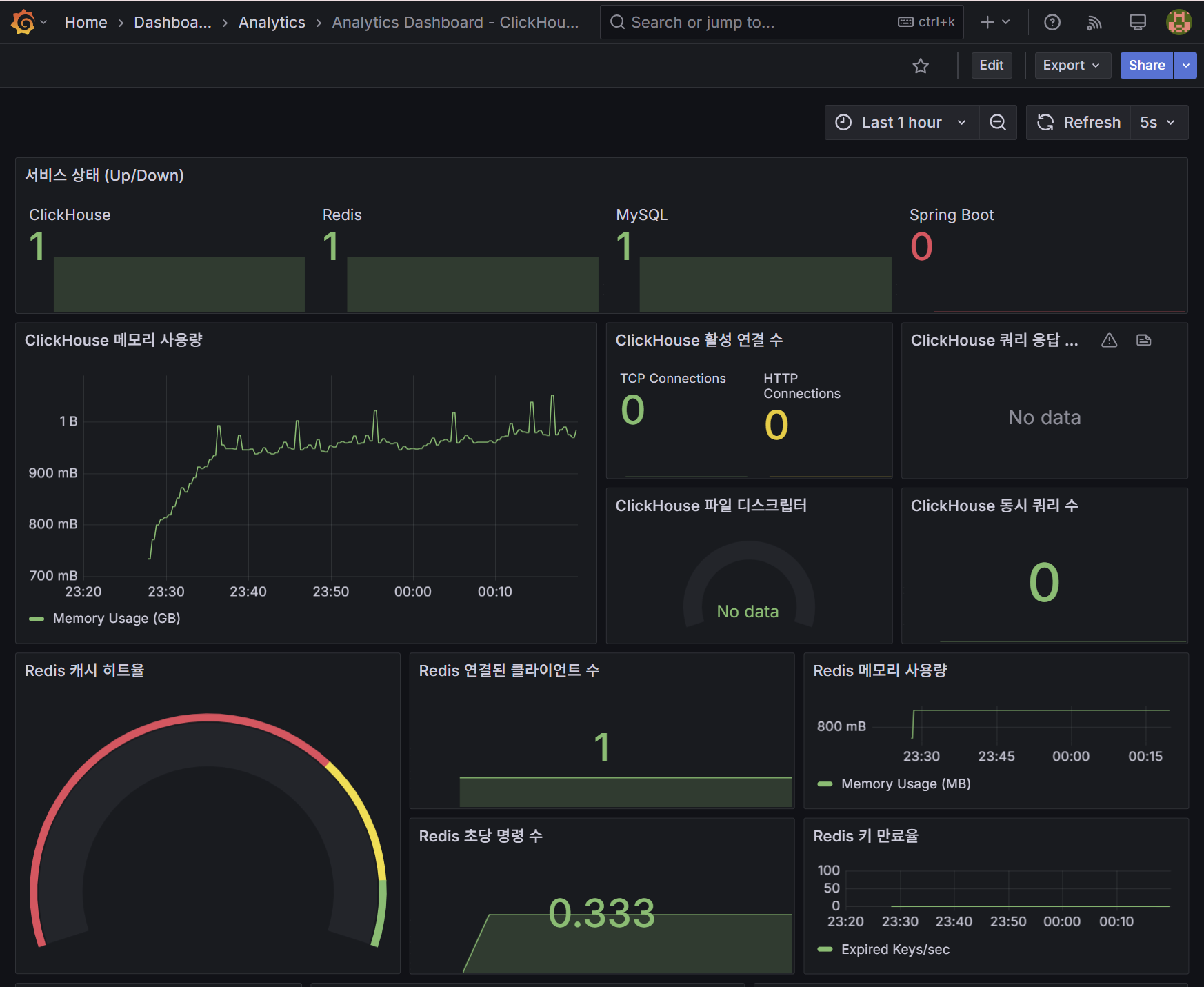
- http://localhost:3000/
- ClickHouse의 경우 내장 메트릭 서버를 사용하므로 활성 연결의 수가 0인 것이 정상이다.
- 반면 Exporter를 사용하는 MySQL, Redis는 1로 되어 있는 것이 정상이다.
Spring Boot와 Prometheus 연결
build.gradle.kts 파일
dependencies { implementation("org.springframework.boot:spring-boot-starter-actuator") runtimeOnly("io.micrometer:micrometer-registry-prometheus") }application.yml
management: endpoints: web: exposure: include: health,info,metrics,prometheus endpoint: health: show-details: always prometheus: metrics: export: enabled: true- 테스트를 위한 최소한의 설정 추가
- http_server_requests 메트릭은 자동 제공
Spring Boot 앱 연결 확인
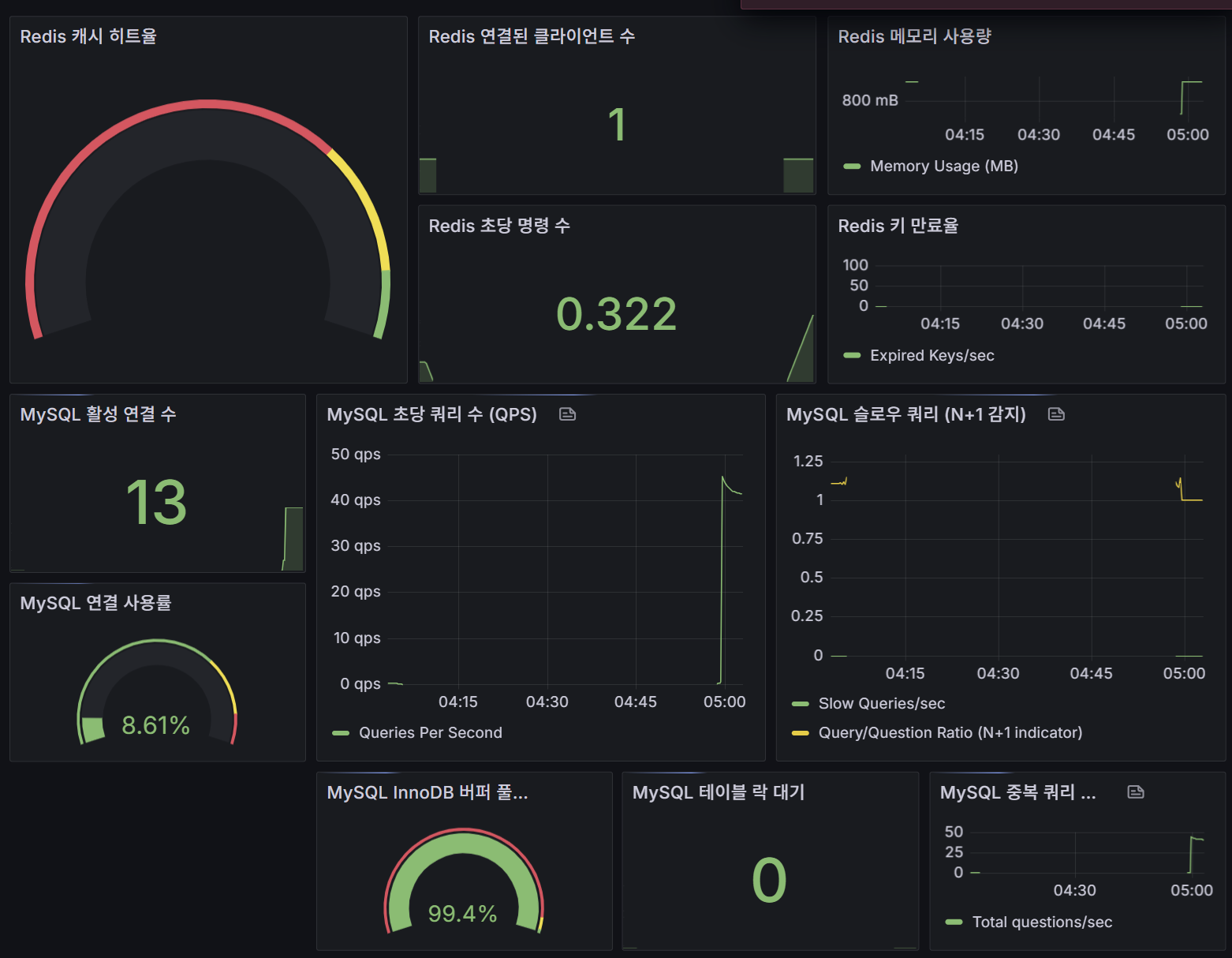
- Spring Boot에서 초기 데이터 적재 시 모니터링
ClickHouse 서버 설정 파일
.xml 파일들을 생성하여 수정하는 것이 ClickHouse를 운영하는 가장 표준적이고 핵심적인 방법이다
ClickHouse 서버 내부 구조 (Docker 내부 구조)
/etc/clickhouse-server/ ├── config.xml # 메인 설정 파일 ├── users.xml # 기본 사용자 설정 파일 ├── config.d/ │ └── *.xml # 커스텀 설정 파일들 └── users.d/ ├── default-user.xml # 기본 사용자 설정 (Docker 환경변수로 자동 생성됨) └── *.xml # 커스텀 사용자 설정 파일들users.xml
- ClickHouse의 기본 사용자 설정 파일
- ClickHouse는 시작할 때 다음 순서로 설정을 로드
/etc/clickhouse-server/users.xml/etc/clickhouse-server/users.d/*.xml
default-user.xml
- 커스텀 사용자 설정 파일
admin 사용자를 설정함에 따라 자동 생성된다.
<default remove="remove"> </default>- 기본
default사용자를 제거하고,admin사용자를 새로 정의
- 기본
프로젝트 폴더 구조
analytics-env/ ├── docker-compose.yml ├── docker-compose.prod.yml ├── .gitignore ├── .env ├── .env.prod ├── .env.example ├── mysql/ │ └── init/ │ └── init.sh ├── grafana/ │ └── provisioning/ │ ├── datasources/ │ │ └── datasources.yml │ └── dashboards/ │ ├── analytics-dashboard.json │ └── dashboard.yml ├── prometheus/ │ ├── prometheus.yml │ └── rules/ │ └── alerts.yml └── clickhouse/ ├── config/ │ └── custom.xml └── users/ ├── default-user.xml └── custom-profiles.xml # 커스텀 사용자 설정 파일
ClickHouse 커스텀 설정 파일 (custom.xml)
<?xml version="1.0"?>
<clickhouse>
<listen_host>0.0.0.0</listen_host>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<logger>
<level>information</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1000M</size>
<count>10</count>
</logger>
<path>/var/lib/clickhouse/</path>
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
<compression>
<case>
<method>lz4</method>
<min_part_size>10000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
</case>
</compression>
<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
<status_info>true</status_info>
</prometheus>
</clickhouse>
로그 설정 (Log Settings)
<logger> <level>information</level> <log>/var/log/clickhouse-server/clickhouse-server.log</log> <errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog> <size>1000M</size> <count>10</count> </logger><level>- 기록할 로그의 상세 수준
- information : 일반적인 정보까지 기록
- warning이나 error : 문제가 발생했을 때만 기록
<log>와<errorlog>- 각각 일반 로그와 에러 로그가 저장될 파일 경로 지정
이렇게 에러 로그를 분리하면 심각한 문제를 빠르게 파악하는 데 도움이 된다
- Docker Compose 볼륨 매핑할 때 적는 그 경로
volumes: - clickhouse_logs:/var/log/clickhouse-server
<size>와<count>- 로그 로테이션(Log Rotation) 설정
<size>- 로그 파일이 지정된 크기에 도달하면 새 파일에 로깅을 시작
<count>- 보관할 옛날 로그 파일의 최대 개수를 지정
데이터 저장 경로 (Data Storage Path)
<path>/var/lib/clickhouse/</path> <tmp_path>/var/lib/clickhouse/tmp/</tmp_path>- 실제 데이터와 임시 파일이 저장될 위치를 지정
<path>테이블, 파티션 등 모든 데이터 파일이 저장되는 가장 핵심적인 경로
- Docker Compose 볼륨 매핑할 때 적는 그 경로
volumes: - clickhouse_data:/var/lib/clickhouse- 기본값과 동일하지만 명시적으로 설정했다
- Docker 볼륨 마운트가 아닌 자체 대용량 디스크 설정을 할 수도 있기 때문
<tmp_path>- 대용량 정렬이나 JOIN 작업 시 메모리가 부족할 때 사용할 임시 파일 저장 경로
- 빠른 디스크(SSD/NVMe)에 이 경로를 지정하면 성능에 도움이 될 수 있다
압축 설정 (Compression Settings)
<compression> <case> <method>lz4</method> <min_part_size>10000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> </case> </compression>- 데이터를 디스크에 저장할 때 사용할 기본 압축 방식을 정의
<method>- 기본 압축 알고리즘 지정
lz4- 압축률은 중간 정도이지만, 압축 해제 속도가 매우 빠르다
- 쿼리 성능에 유리하기 때문에 기본값으로 널리 사용된다
<min_part_size>와<min_part_size_ratio>- 압축 효율을 위한 세부 조건
- 데이터 조각(Part)이 너무 작을 때는 압축의 이점보다 오버헤드가 더 클 수 있다
- 따라서 특정 크기(예: 10MB) 이상일 때만 압축을 적용하도록 설정
커스텀 설정 확인 방법
데이터 경로 설정 확인
docker-compose exec clickhouse sh -c "ls -la /var/lib/clickhouse/"- tmp 폴더도 생성되어 있음을 확인할 수 있다.
로그 설정 확인
docker-compose exec clickhouse sh -c "ls -la /var/log/clickhouse-server/"결과
river@BOOK-VKBCE9E5R0 MINGW64 ~/git/analytics-env (main) $ docker-compose exec clickhouse sh -c "ls -la /var/log/clickhouse-server/" total 24308 drwxrwxrwx 2 clickhouse clickhouse 4096 Aug 20 22:48 . drwxr-xr-x 1 root root 4096 Jul 29 16:49 .. -rw-r----- 1 clickhouse clickhouse 206158 Aug 21 02:14 clickhouse-server.err.log -rw-r----- 1 clickhouse clickhouse 24665421 Aug 21 02:31 clickhouse-server.log
ClickHouse 커스텀 사용자 파일 (custom-profiles.xml)
<?xml version="1.0"?>
<clickhouse>
<profiles>
<readonly>
<readonly>1</readonly>
<max_memory_usage>2G</max_memory_usage>
<max_execution_time>60</max_execution_time>
</readonly>
<spring>
<readonly>0</readonly>
<max_memory_usage>2G</max_memory_usage>
<max_execution_time>60</max_execution_time>
<max_threads>8</max_threads>
<max_bytes_before_external_group_by>512M</max_bytes_before_external_group_by>
<max_bytes_before_external_sort>512M</max_bytes_before_external_sort>
</spring>
</profiles>
</clickhouse>
사용자 설정 (Users Settings)
- 현업에서는 모든 권한을 가진 admin 계정 하나로 모든 것을 처리하지 않는다
- 데이터베이스에 접속할 수 있는 개별 사용자 계정을 생성하고 권한을 설정한다.
- 다만, xml 파일로 사용자를 설정하는 것보다 SQL로 동적으로 생성하는 것이 좋다
- 미리 xml 파일에서 프로파일을 설정해두고 SQL로 프로파일을 할당할 수 있다
프로파일 설정 (Profile Settings)
<profiles> <spring> <readonly>0</readonly> <max_memory_usage>2G</max_memory_usage> <max_execution_time>60</max_execution_time> <max_threads>8</max_threads> <max_bytes_before_external_group_by>512M</max_bytes_before_external_group_by> <max_bytes_before_external_sort>512M</max_bytes_before_external_sort> </spring> </profiles>- 사용자에게 적용할 수 있는 규칙과 자원 제한의 묶음
- 여러 사용자에게 동일한 정책을 쉽게 적용할 수 있어 관리가 편리
<readonly>프로파일- 태그 이름(
readonly)이 프로파일의 이름이다.
- 태그 이름(
<readonly>1</readonly>- 전체 시스템에 대한 읽기 전용 설정
- 모든 데이터베이스 적용
- DDL 명령어(CREATE, DROP, ALTER) 완전 차단
- 이 프로파일이 적용된 사용자에게 SELECT와 같은 읽기 작업만 허용
- 매우 강력한 설정으로 실수로라도 데이터를 수정하거나 삭제하는 것을 원천적으로 차단
- 전체 시스템에 대한 읽기 전용 설정
<max_memory_usage>- 해당 사용자가 날리는 단일 쿼리가 사용할 수 있는 최대 메모리를 5GB로 제한
config.xml의 서버 전체 설정보다 우선 적용
<max_execution_time>- 쿼리가 최대 300초까지만 실행되도록 제한
- 악성 쿼리가 서버 자원을 무한정 점유하는 것을 방지하는 중요한 설정
<max_memory_usage>- 동시에 실행할 수 있는 스레드 수
- 병렬 쿼리 처리용 (서버 CPU 코어 수에 따라 조정)
max_bytes_before_external_*- 큰 쿼리 시 디스크 spill 허용 (Out of memory 방지)
- 임시 데이터 저장에 쓸 최대 공간
SQL로 사용자 프로파일 지정
-- readonly 프로파일 사용하는 사용자 CREATE USER readonly_user IDENTIFIED BY 'password' SETTINGS PROFILE 'readonly'; -- spring 프로파일 사용하는 사용자 CREATE USER spring_user IDENTIFIED BY 'password' SETTINGS PROFILE 'spring'; -- 또는 기존 사용자에게 프로파일 변경 ALTER USER readonly_user SETTINGS PROFILE 'readonly';프로파일 설정 확인 방법
컨테이너 접속
docker-compose exec clickhouse clickhouse-client --user=admin --password=1234프로파일 설정 확인 SQL 명령어
-- 모든 프로파일 목록 SELECT * FROM system.settings_profiles; -- 특정 프로파일의 설정 내용 SELECT * FROM system.settings_profile_elements WHERE profile_name = 'spring'; -- 사용자별 프로파일 확인 SELECT * FROM system.settings_profile_elements WHERE user_name IS NOT NULL;- ‘spring’ 프로파일의 설정 내용
SELECT * FROM system.settings_profile_elements WHERE profile_name = 'spring' Query id: ac9bde5f-6cd3-45f4-a7e8-b87619fbec19 ┌─profile_name─┬─user_name─┬─role_name─┬─index─┬─setting_name───────────────────────┬─value──────┬─min──┬─max──┬─writability─┬─inherit_profile─┐ 1. │ spring │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 0 │ readonly │ 0 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 2. │ spring │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 1 │ max_memory_usage │ 2000000000 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 3. │ spring │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 2 │ max_execution_time │ 60 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 4. │ spring │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 3 │ max_threads │ 8 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 5. │ spring │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 4 │ max_bytes_before_external_group_by │ 512000000 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 6. │ spring │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ 5 │ max_bytes_before_external_sort │ 512000000 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ └──────────────┴───────────┴───────────┴───────┴────────────────────────────────────┴────────────┴──────┴──────┴─────────────┴─────────────────┘ 6 rows in set. Elapsed: 0.002 sec. - 사용자별 프로파일 확인
SELECT * FROM system.settings_profile_elements WHERE user_name IS NOT NULL Query id: 2bd6bf08-346a-4e69-8006-809e1bcca5de ┌─profile_name─┬─user_name───┬─role_name─┬─index─┬─setting_name─┬─value─┬─min──┬─max──┬─writability─┬─inherit_profile─┐ 1. │ ᴺᵁᴸᴸ │ admin │ ᴺᵁᴸᴸ │ 0 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ default │ 2. │ ᴺᵁᴸᴸ │ spring_user │ ᴺᵁᴸᴸ │ 0 │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ ᴺᵁᴸᴸ │ spring │ └──────────────┴─────────────┴───────────┴───────┴──────────────┴───────┴──────┴──────┴─────────────┴─────────────────┘ 2 rows in set. Elapsed: 0.004 sec.
- ‘spring’ 프로파일의 설정 내용